缓存穿透、缓存并发、缓存失效之思路变迁
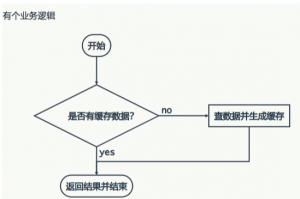
作者从缓存实战中最常遇到的三类“坑”出发,分别剖析了问题的成因与演进式的解决思路。缓存穿透源于无效请求击穿缓存层直击数据库,作者提出了用特殊值预占位的拦截技巧。缓存并发则针对高并发下缓存瞬间失效带来的数据库压力,给出了加锁串行化的方案。缓存失效问题本质是缓存集体过期导致的雪崩,通过引入随机因子分散过期时间是关键。文章后半部分通过问答,进一步探讨了缓存与数据库的一致性等更深层的实践困惑,整体展现了从发现问题、分析根因到提出并优化方案的完整思考过程。
共 17 篇相关文章
作者从缓存实战中最常遇到的三类“坑”出发,分别剖析了问题的成因与演进式的解决思路。缓存穿透源于无效请求击穿缓存层直击数据库,作者提出了用特殊值预占位的拦截技巧。缓存并发则针对高并发下缓存瞬间失效带来的数据库压力,给出了加锁串行化的方案。缓存失效问题本质是缓存集体过期导致的雪崩,通过引入随机因子分散过期时间是关键。文章后半部分通过问答,进一步探讨了缓存与数据库的一致性等更深层的实践困惑,整体展现了从发现问题、分析根因到提出并优化方案的完整思考过程。
这篇讲的是微信朋友圈在面临十亿级日发布、百亿级日浏览的海量压力时,如何保障系统稳定与性能的核心架构。 微信朋友圈负责人陈明分享了其背后的技术之道。面对移动互联网汹涌的峰值流量(如春节期间流量达平日5倍),系统通过一套自动化的服务优先级策略进行应对:优先保障支付与点对点消息,然后是群聊,最后才是朋友圈。在核心架构上,朋友圈采用“写扩散”模型——用户发布内容时,会将数据副本写入每个好友的时间线表。这种看似“重”的写入,换来了极其简单可靠的读取(只读自己的时间线),大幅降低了读失败的可能性。 文章还揭示了朋友圈数据依赖的四个核心表(发布、相册、评论、时间线)及其水平扩展方式,并详细阐述了多层级容灾设计。从同城多园区无感切换,到全球多数据中心的跨地域同步,微信甚至为适应高延迟、高丢包的跨国公网环境,自研了类TCP协议以保证数据同步的效率与安全。 整个分享从数据背景、架构选型到容灾细节,清晰展示了一个超大规模社交系统如何在性能与可靠性之间做出权衡与设计。
这篇文章通过生动的比喻和生活中的实例,系统讲解了集群与负载均衡这些听起来高深、实则贴近实际的核心技术概念。 作者从最常见的误解切入,解释了集群的本质是多台计算机“联合工作”,而负载均衡的核心则是“分摊压力”。最巧妙的部分在于用“兄弟开店”的比喻清晰区分了三种集群类型:负载均衡集群如同“老大接单,兄弟们分工干活”;高可用集群则通过“兄弟互相备份”来保障服务不中断,并详细解释了双机热备、双工、互备等模式;高性能计算集群则好比“父子齐上阵,合力赶制复杂家具”。这些比喻让抽象的架构概念变得异常直观。 文章并非泛泛而谈概念,而是明确了它们各自的典型应用场景,比如超市收银对应负载均衡,早餐铺高峰时段对应高可用保障。同时也指出了掌握这些技术的门槛,强调其需要运维、架构、开发等多方面的实践知识积累,而不仅仅是理论理解。
这篇讲的是淘宝搜索的Pora2实时分析系统在大量使用HBase进行高并发读写时,所遇到的一系列性能“坑”及优化实践。系统上线后出现处理延迟、集群压力大的问题,排查发现根源主要在于HBase的使用方式。 文章拆解了几个典型案例:一是HBase默认的Periodic Flusher机制引发了过于频繁的flush与compact,通过调整其超时阈值得到了缓解;二是下游消费消息队列时未控制Scan频率,对Region Server造成了无谓压力;三是在超大并发下,过多的客户端连接耗尽了服务端Handler,作者的解决方案是减少进程数、增加线程数以复用连接。 此外,还涉及了因rowkey生成代码bug导致的数据访问热点,以及Bulk Load数据未做Major Compaction引起的读取性能衰减。文章最后总结道,高并发场景下必须合理使用HBase,避免不当操作形成“越慢越压、越压越慢”的恶性循环。这些从实战中沉淀的细节,对同类系统的设计与调优很有参考价值。
这篇讲的是在网站流量激增、Nginx压力陡增时,如何通过调整几个核心配置参数来稳住性能。作者直接切入实战场景:当默认配置拖了高并发后腿,该从哪里下手优化。文章聚焦于几个经线上流量验证有效的关键参数,比如通过调大worker_connections来提升并发处理能力、调整keepalive参数减少连接建立开销、优化缓冲区大小以避免磁盘I/O瓶颈等,每个参数都解释了它在高负荷下的作用原理和推荐值范围。不同于泛泛的理论讲解,这篇内容是基于真实流量增长的观察与调整,总结出了在资源有限时最应优先关注的配置项,帮助运维或开发同学快速定位到性能提升的杠杆点。
这篇讲的是如何用Redis设计一个类似12306的高并发抢票系统。作者从网上热议的“如何实现12306”问题出发,认为这是检验架构能力的绝佳场景。文章没有空谈理论,而是聚焦于如何利用Redis的原子操作、高效数据结构和发布订阅等特性,来解决库存扣减、订单锁定和削峰填谷等核心挑战。作者详细展示了关键环节的实现思路,比如如何用Lua脚本保证扣减的原子性,以及如何设计数据结构来快速查询余票,让方案既具备高并发能力,又兼顾了数据一致性。最后,文章还探讨了如何利用Redis的监控和持久化机制来保障系统稳定性,给出了从原型到保护的完整思考路径。
这篇讲的是作者对“铁路订票网站12306技术复杂性”这一公开讨论的直接回应。他针对当时关于系统设计难度的言论,提出了一个相当具体且大胆的技术判断:这个系统的设计挑战被夸大了。 作者从自身技术经验出发,给出了一个清晰的估算:在他看来,支撑起12306的核心订票功能,一个2人的小团队,在2周的时间内,配合40台服务器的硬件资源,就足以完成开发和部署。这个结论并非泛泛而谈,而是给出了明确的团队规模、时间周期和资源配比,将一个宏大的系统工程问题解构成了可执行、可衡量的具体方案。 文章的价值在于,它跳出了对系统复杂性的敬畏情绪,用一种工程师的务实视角,对技术问题进行了“降维”分析。这种将庞大系统拆解为最小可行单元进行思考的方式,或许能给面临类似复杂工程挑战的技术人,带来一种新的、更富信心的审视角度。
这篇讲的是如何从头开始为Nginx编写自定义模块。作者从Nginx模块化架构的背景出发,拆解了模块开发中最核心的几个要素:模块配置结构体、指令定义以及处理函数(handler)的编写逻辑。文章没有停留在理论层面,而是通过一个具体的计数器模块示例,演示了从定义指令、处理配置到实现业务逻辑的全流程,并展示了如何将模块编译进Nginx。 其中比较巧妙的地方在于,作者解释了如何利用Nginx的链表结构来管理模块配置,并强调了在handler中注意内存池使用和请求体读取的关键细节,这能帮助新手避开常见的坑。文章还对比了content filter和log handler等不同类型模块的适用场景,让读者知道在什么情况下该选用哪种开发模式。 整体来看,这篇文章把模块开发的骨架清晰地勾勒了出来,对于想动手实践的开发者来说,跟着走一遍流程,就能对Nginx的模块化设计有更直观的理解。
这篇讲的是如何用Facebook开源的Scribe搭建分布式日志系统。作者从实际需求出发,介绍了Scribe的核心优势:它通过thrift协议传输日志,能轻松整合不同语言的项目,实现从本地到远程的统一日志收集。在性能上,Scribe示例配置的并发量可达每秒200万条消息,对于绝大多数应用来说,即便是最基础的配置也能保证远程日志收集的可靠性。如果遇到更高压力,还可以通过主从架构自动同步日志到本地,进一步提升稳定性。文章接下来会具体演示Scribe的安装与配置过程。
这篇讲的是一个厂内服务框架三年的演变与实战经验。 这个框架目前已部署超过2000个服务,日均执行次数稳定在120亿、峰值达150亿,规模相当可观。文章核心并非展示光鲜架构,而是作者坦诚分享这三年“摔过的跤”——由于早期经验不足,在框架广泛使用后不得不进行艰难的补救与重构。作者回顾了这个从零到大规模应用的全过程,总结了那些因规划不周而踩下的坑。 对于计划构建服务框架或推进服务化的团队,这篇最大的价值在于它的务实。它没有鼓吹一步到位的理想方案,而是强调在项目初期就应做好哪些关键铺垫,如何避免框架成型后因设计缺陷而被迫进行大改。这些来自大规模生产环境的第一手教训,能帮助读者在起步阶段就建立更稳健的基线。
这篇讲的是技术领域中“妄想症”和“狂热者”现象的深入分析。作者从AI算法和系统设计的角度出发,探讨了当模型表现出过度自信或偏执行为时,可能带来的风险和挑战。文章指出,“妄想症”常出现在机器学习模型中,表现为对错误预测的过度确信,这类似于人类心理学中的妄想症,但在这里指技术系统的缺陷——比如一个图像分类器在噪声干扰下仍坚持错误标签,却无视真实数据分布。而“狂热者”则类似于
这篇讲的是Web2.0热潮中对“用户生成内容”(UGC)的一场深度反思。作者从2006-2007年行业对“UGC引领未来”的集体鼓吹,以及一个年轻人充满困惑的提问出发,冷静剖析了UGC模式的核心矛盾。 文章并未止步于简单的肯定或否定,而是提出了一个关键视角:真正驱动内容生态价值的,往往是那些被称为“高手”的核心创作者。作者指出,纯粹依赖海量普通用户生成内容,容易导致信息过载与质量平庸。平台若想获得持久的生命力,其真正作用在于识别、吸引并服务好这些“高手”,为他们提供创作的土壤与分发的舞台,而非一味追求“全民创作”的表象。 这篇文章超越了当年非“泡沫”即“风口”的二元争论,将讨论引向了内容平台建设中更本质的问题:数量与质量如何平衡,平台的核心杠杆点究竟在哪里。对于今天思考社区运营、内容平台甚至AI生成内容价值的读者而言,其中关于“高手”生态的论述,依然能带来关于内容本质的清醒启发。
这篇讲的是如何系统性降低应用延迟的实战方法论。作者从团队日常的技术交流实践出发,将零散的优化经验提炼成可复用的思路,核心聚焦在“latency”这个影响用户体验的关键指标上。 文章没有停留在理论层面,而是结合了具体的优化场景进行拆解。比如前端可以优化的关键渲染路径、减少关键请求阻塞,后端则涉及服务依赖梳理、异步化改造以及更高效的数据结构选择。作者还强调了度量和监控的重要性,指出优化必须建立在真实的数据反馈之上,而非主观猜测。 这些方法并非孤立存在,而是形成了一套组合拳。文章通过分享这些具体的优化点,为读者提供了一份可直接落地的检查清单,帮助开发者在实际项目中快速定位性能瓶颈并找到对应的解决策略。
这篇讲的是腾讯控股在近期遭遇的股价震荡与深层创新挑战。文章开篇便列出一组引人注目的数据:在6月4日至10日的五个交易日内,腾讯控股股价重挫15%,放量击穿年线,而同期恒生指数基本持平。这种背离市场整体的显著下跌,往往暗示着公司自身或其所在领域出现了值得深思的结构性问题。 作者随即点出矛盾的核心——即便拥有同时在线人数超过1亿的QQ这个堪称中国互联网的奇迹,成功本身也可能埋下挑战的种子。文章的视角并未停留在股价波动表象,而是借此事件展开,审视这家中国最成功的互联网企业,在辉煌成就背后所面临的巨大压力,特别是关于创新动力与未来路径的拷问。 对于关注科技产业与商业逻辑的读者而言,这篇文章提供了一个观察巨头的新角度:当增长面临瓶颈、市场信心出现波动时,一家以产品和用户著称的公司,该如何重新激活自身的创新引擎。它探讨的已不仅是腾讯的个案,也折射出中国互联网第一代领军者普遍面临的“成功后的挑战”。
这篇讲的是如何让QQ游戏的同时在线人数突破百万的技术架构与实现。作者从早期QQ游戏大厅的架构演进出发,核心剖析了支撑百万级并发的几大支柱:包括采用无状态接入层与分布式网关,实现用户连接的横向扩展;通过玩家状态分区与精准广播,高效处理海量游戏房间内的实时消息同步;以及利用数据库分库分表与缓存策略,解决用户数据持久化的性能瓶颈。 文章不仅回顾了从百万到千万在线过程中踩过的坑(如缓存雪崩、热点房间问题),也分享了其技术选型背后的思考。例如,在保证低延迟和高可靠性的前提下,如何权衡了自研与通用中间件的使用。最终,这套架构稳定支撑了休闲游戏、棋牌游戏等多种产品形态的爆发式增长。 整个分享紧扣“高并发”这一核心,给出了从理论到落地的完整实践路径,对于理解大规模在线系统的工程化构建有很强的参考意义。
这篇文章从Web 2.0时代网站面临的现实挑战切入,探讨了传统关系型数据库为何会显得力不从心。作者指出,当面对超大规模数据和高并发的读写需求时,关系数据库在横向扩展、数据模型灵活性等方面遭遇了瓶颈。 文章的核心在于对比分析。它阐明了非关系数据库(NoSQL)如何通过分布式架构、灵活的数据模型(如键值、文档、列族)来更好地应对这些挑战。关键差异在于,NoSQL为了可扩展性和性能,在设计上牺牲了传统ACID事务的一些特性,转而追求最终一致性等不同的数据保障模型。 作者进而说明,这两类数据库并非替代关系,而是适用于不同场景。关系数据库依然是强一致性事务和复杂查询的首选;而NoSQL则在大规模、高吞吐的互联网应用,如社交网络、实时分析和内容管理中大放异彩。这篇分析帮助读者理清了技术选型的思路:没有最好的数据库,只有最适合特定业务场景的数据库。
这篇讲的是博客积分排名系统如何实现实时更新的问题。文章从用户视角出发——当写完一篇文章后,能立刻看到自己的排名变化,比如百分比从 Top 3.27% 提升到 3.16%,这种即时反馈对许多博主(比如文中提到的“晓文哥”)很有吸引力。 为了解决这种高并发的实时排名需求,作者提出使用跳表(Skip List)作为核心数据结构。跳表能高效支持频繁的插入、删除和查询,非常适合动态变化的排行榜场景。文章探讨了在积分频繁变动的情况下,如何利用跳表的有序性与多级索引来快速定位和更新排名,从而避免传统方案可能带来的性能瓶颈。 这种设计让排行榜能快速响应积分变动,既满足用户的即时反馈需求,又保证了系统的稳定性。对于需要构建实时排行榜或类似高频更新场景的开发者来说,这个方案提供了具体的思路参考。