移动web开发调试工具AlloyLever介绍
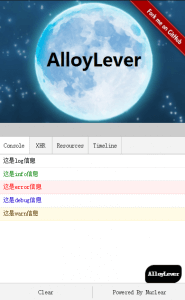
这篇介绍的是AlloyLever,一个轻量但功能强大的移动端Web调试工具。它直接解决了移动调试的三大高频痛点:查看日志(Log)、捕获脚本错误(Error)、监控网络请求(AJAX)。 与开发者需要连接电脑调试不同,AlloyLever通过在页面中注入一个JS文件,就能提供一个类似桌面浏览器DevTools的浮动面板。它巧妙地通过重写`console`方法和`XMLHttpRequest`对象,来拦截并记录所有的日志输出、JS错误、资源加载失败以及XHR请求的完整生命周期。同时,它也能展示Cookie、LocalStorage和页面性能时间线。 这种“注入即用”的设计,极大地降低了移动端调试的门槛,特别适合在真机上快速定位问题。文章还清晰地拆解了其实现原理,比如如何通过回调检查AJAX状态来捕获响应数据,可读性很高。对于常做移动端开发的团队来说,这是一个能显著提升排错效率的实用工具。文章末尾也提到了微信团队的vConsole,方便读者对比选择。