C++ 中的 main 定义
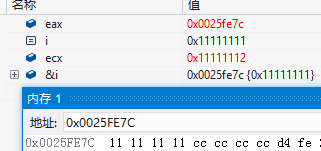
这篇讲的是 C++ 最新标准里一个看似微小却影响行为的细节调整:关于 `main` 函数的定义。 作者直接指出了核心变化——根据最新的 C++ 标准草案,程序入口函数 `main` 不再允许被 `extern "C"` 这样的 linkage-specification 修饰。文章引用了标准原文,明确了这一点。对于很多习惯了在某些项目或编译器下这样写来避免名字修饰的开发者来说,这可能会造成困惑或编译错误。 文章进一步解释了背景:在旧标准和实际编译器实现中,`main` 作为程序入口点,其链接约定有着特殊的隐含处理。允许用 `extern "C"` 修饰是一种非正式的宽容行为,但新标准明确了这一行为是不符合规定的。文章通过展示错误用法与正确用法的代码对比,清晰地指明了正确做法——只需遵循基本的 `main` 函数签名即可。 这提醒我们,依赖编译器的“非标准特性”或历史宽容行为存在风险。随着标准演进,这些模糊地带正在被澄清。对于需要严格符合标准的代码,尤其是跨平台项目,留意此类细节更新很有必要。