HTML代码到底该不该压缩
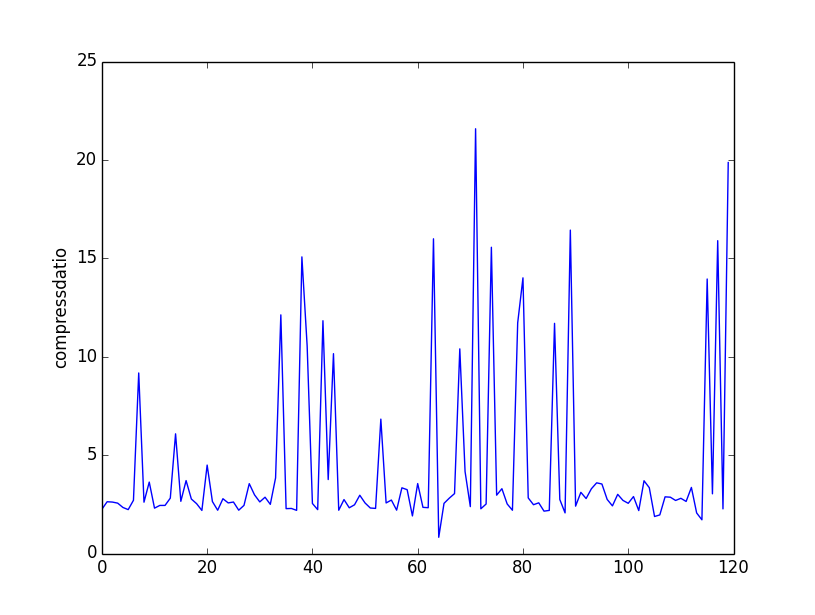
这篇文章从一个常见问题出发:开发者常问如何让静态缓存插件支持HTML压缩。作者没有直接讨论实现,而是通过数据分析来探讨HTML代码压缩在今天是否仍有实际意义。 作者首先解释了HTML压缩的本质——主要删除空格、制表符、注释等文本中有意义但浏览器显示时非必要的字符。通过一个Python脚本对100个网页的实测,他发现HTML压缩率最高可超过20%。然而,真正的关键在于后续的对比分析。作者进一步用实验比较了原始HTML、仅HTML压缩、仅Gzip压缩以及“HTML压缩后再Gzip压缩”这四种情况下的文件大小。 数据图表清晰地揭示了两个核心结论:一是HTML压缩带来的空间节省,仅在原始文件较大时才相对明显;二是在服务器已开启广泛使用的Gzip压缩的前提下,网页本身是否经过HTML压缩,对最终传输体积的影响微乎其微。因此,对于大多数网站而言,这种压缩对性能提升意义有限,反而可能影响开发调试效率。 文章最后补充了一个有趣的视角:在像Google这样流量占全球近40%的超大规模场景下,即使是单次请求节省一个字节,累积起来也是巨大的流量成本节省。这说明任何优化的价值,都需要结合实际的应用规模和上下文来评判。