Dynamo和Cassandra海量存储基础
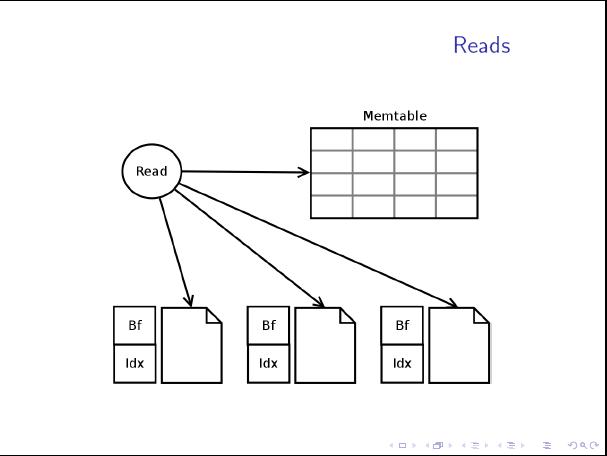
这篇讲的是Dynamo和Cassandra这两个经典分布式存储系统,在核心设计哲学上的对比与剖析。文章从它们共享的基石概念入手,比如用W+R>N公式如何决定读写一致性级别,并用主备复制、Quorum机制等实例具体说明了N、W、R取值的影响。 真正的分歧点在于处理数据冲突的策略。Dynamo选择了更复杂的向量时钟,它像Git一样记录数据版本的来源,当检测到并行的、可能冲突的写入时,会保留所有版本交由应用层合并,适合能处理合并逻辑的场景。而Cassandra则采取了更粗暴的简化——时间戳方案,它不检测冲突,直接以最新时间戳的数据为准。这极大降低了复杂度,适用于大多数对冲突不敏感的场景。 文章还追溯了两者共同的基础——Gossip协议,并提及了它在去中心化通信中的优势与维持一致性的挑战。作者的对比最终导向了一个深刻的观点:在大多数写入冲突概率较低的场景下,这种最终一致性模型比强一致全局排序(如Paxos)更高效。两种不同的冲突解决路径,正体现了在工程化实现中对一致性权衡的不同哲学。