应用层的容错与分层设计
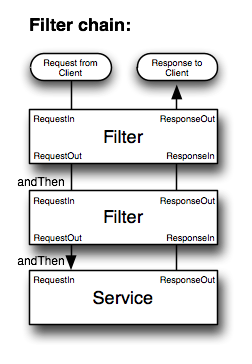
这篇讲的是分布式系统中,如何为应用层远程调用构建健壮容错体系的实践思考。文章从实际项目问题出发,指出系统内部服务间远程调用的不可靠性——无论是网络波动、硬件故障还是服务本身变慢,都可能像多米诺骨牌一样拖垮整个系统。单纯依赖服务端容错还不够,调用端(应用层)必须有独立的防御设计。 作者以微博团队的实践为例,分享了不同场景下的容错策略:访问MySQL时,写操作直接抛异常,读操作则有多级Failover;连接Redis或Memcached则需设置超时、异常标记、定期探测,并通过一致性哈希切换到备份节点;调用HTTP接口则要短超时、谨慎重试,并配合业务降级。 这些分散的实现暴露了问题:各客户端独立编码,原理相通却无法复用,维护成本高,且同步调用消耗大量线程资源。文章进而探讨了统一解决方案的可能性,参考了Twitter的Finagle框架思路——将容错、重试等策略抽象为“Filter”,与服务和Future模型结合,实现异步化的通用网络客户端。一个理想的统一client应该具备分层设计(服务层、网络层)、可扩展协议支持,并内置负载均衡、Failover等高可用能力,最终让开发者更专注于业务逻辑而非繁琐的容错细节。