一致性哈希算法(consistent hashing)
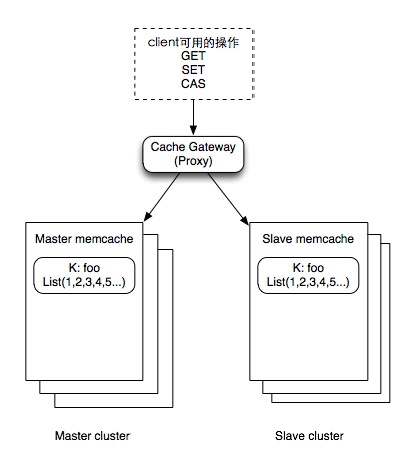
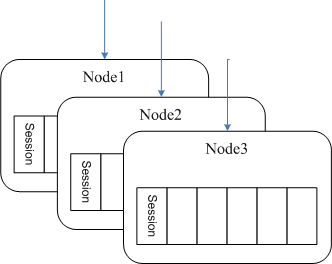
这篇讲的是分布式系统中一个经典问题的优雅解法:一致性哈希算法。作者从最简单的哈希取模(id % N)方式切入,指出其致命短板——一旦集群节点数(N)因扩容或宕机而变化,几乎所有数据的映射关系都会被打破,导致缓存雪崩,后端压力骤增。 为了解决这个“牵一发而动全身”的问题,一致性哈希将哈希空间组织成一个虚拟的环形。节点被映射到环上,数据也映射到环上,并沿顺时针方向找到的第一个节点作为处理者。这样,当增加或删除节点时,只有相邻节点间的数据映射会发生变化,实现了影响范围的局部化。 文章进一步指出,若物理节点较少,可能导致负载在环上分布不均。为此引入了“虚拟节点”概念——为每个物理节点生成多个虚拟分身,均匀分布在环中,从而使负载更加均衡,但会增加一次查找开销。 最后,文章还归纳了评判一致性哈希算法优劣的四个核心标准:平衡性、单调性、分散性和负载。这篇内容清晰地将一个解决分布式数据路由问题的核心算法,从痛点、原理到优化与评估,串联成了一条完整的逻辑链。