可伸缩性架构常用技术——之数据切分(Data Sharding/Partition)
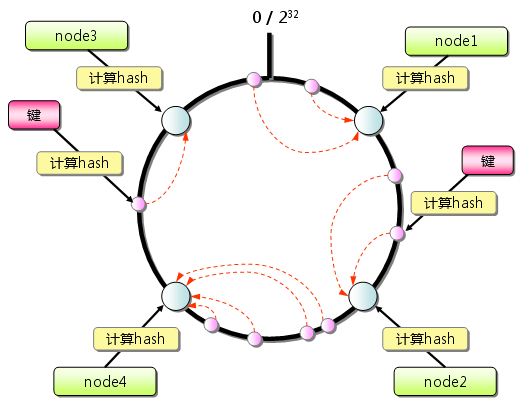
这篇讲的是在应对大规模数据场景时,系统架构如何通过“数据切分”来打破单点瓶颈。文章从背景出发,解释了当数据量和访问压力增长时,单一数据库难以承载的痛点,然后系统性地介绍了数据切分(Sharding/Partition)的核心思路。 作者将切分策略主要分为两类:水平切分与垂直切分。水平切分是把同一张表的数据,按照某个字段(如用户ID)的规则(如哈希取模)分散到多个库表中,让数据容量和写入压力得以线性扩展;垂直切分则是将一张宽表的列拆分到不同的库,主要解决单行数据过大或访问频率不均的问题。文章还对比了常见的路由算法(如范围、哈希)以及它们在不同业务场景下的权衡,比如哈希分片能均匀分布数据但范围查询效率低,而范围分片利于区间查询却可能产生热点。 最后,文章没有回避切分后带来的挑战,比如跨分片查询、分布式事务和全局唯一ID等复杂问题,并点明了合理的数据切分是兼顾性能与复杂度的关键一步。整篇文章逻辑清晰,从问题到方案再到后续影响,为需要处理海量数据的开发者提供了一份切实的架构思路参考。