分布式缓存的一起问题
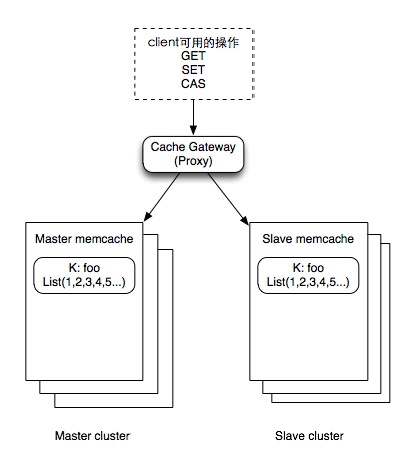
这篇文章聚焦于分布式缓存主从架构中一个典型的“踩坑”场景:当master节点突发故障时,原本设计用于保障数据一致性的CAS(Compare-and-Swap)流程却会导致slave副本数据静默过期。作者从实际业务故障出发,剖析了问题根源——master cas失败后并未对slave执行set操作,导致新变更无法写入缓存。 文章进一步探讨了自动切换master角色为何不可行,以及手工切换或采用“delete slave”或“设置短过期”等补救方案时,仍需面对命中率下降、接口职责模糊等棘手权衡。最终,作者将问题抛回给读者:在这种对可用性与一致性都有要求的场景下,一个更完美的解决方案应该如何设计?