记录一种工作流心跳机制的设计
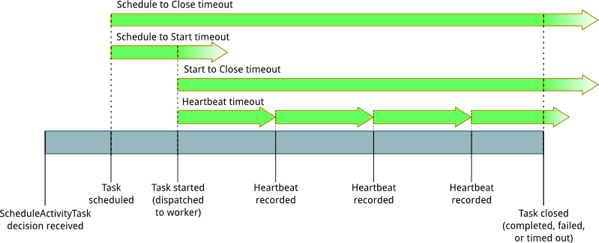
这篇讲的是在基于Amazon SWF的工作流中,如何设计一个可靠的心跳机制来维持长时间任务的存活。作者从实际开发踩坑出发,分享了应对SWF 5分钟超时限制的解决方案。 核心方案是采用两个双端队列(main queue和backup queue)来统一管理所有需要心跳的任务。每秒从主队列取出一个任务发送心跳,完成后放入备份队列;每两分钟(一个周期)再将备份队列的任务批量移回主队列,开始新一轮循环。这个设计巧妙地解决了并发下的任务状态跟踪问题,比单队列加计数器的方案更简单高效。 文章深入探讨了几个关键设计考量:心跳频率并非越快越好,需要在及时性和避免服务端限流之间做权衡;周期长度(如120秒)的设置要能覆盖超时时间并提供重试余地。更重要的是,作者详细剖析了心跳失败时的分级处理策略:对于资源已取消等常规异常直接移除任务;对于限流错误立即重试;对于其他未知异常则放入当前周期队尾重试并计数,避免影响其他任务。 最后,通过一个EMR集群因心跳超时和检查逻辑缺陷被误回收的实例,说明了在真实分布式环境中,看似简单的心跳机制与任务超时、资源监控等环节环环相扣,设计时需要全局考量,用绝对时间而非操作次数来判断状态才更可靠。