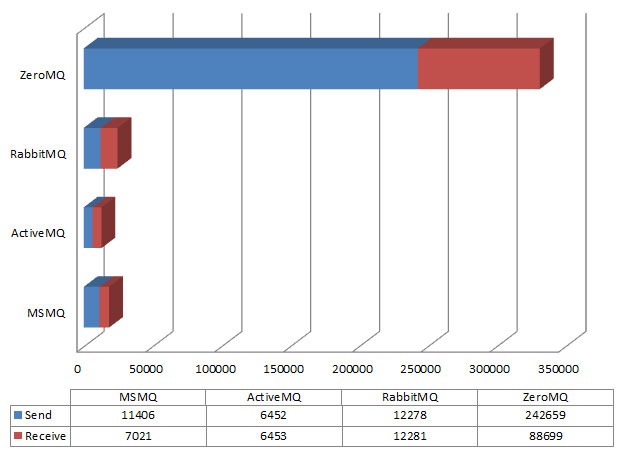
构建C1000K的服务器(2) – 实现百万连接的comet服务器
这篇讲的是作者如何从零实现一个支持百万并发连接的Comet服务器。在解决了系统内核参数调整的基础问题后,文章将焦点转向了具体的应用实现。 作者选择用C/C++和libevent来构建核心,重点在于如何高效管理百万级的连接与通道。一个巧妙的设计是:服务器启动时便预先分配好100万个通道对象,而动态的订阅者则通过内存池管理,这使得初始内存占用控制在24MB。 最吸引人的是文章展示的实测数据。通过逐步增加连接数进行压力测试,结果非常直观:每个Comet连接大约只消耗2.7KB内存。最终,在支撑100万空闲连接时,进程总内存占用约2.7GB,而CPU使用率维持在0%。这清晰证明了该架构在高并发、低活跃度场景下的高效性。 项目的代码已在GitHub开源,文章提供的测试方法和详细数据,为需要构建类似长轮询服务的开发者提供了一个扎实的参考范例。