blktrace未公开选项网络保存截取数据
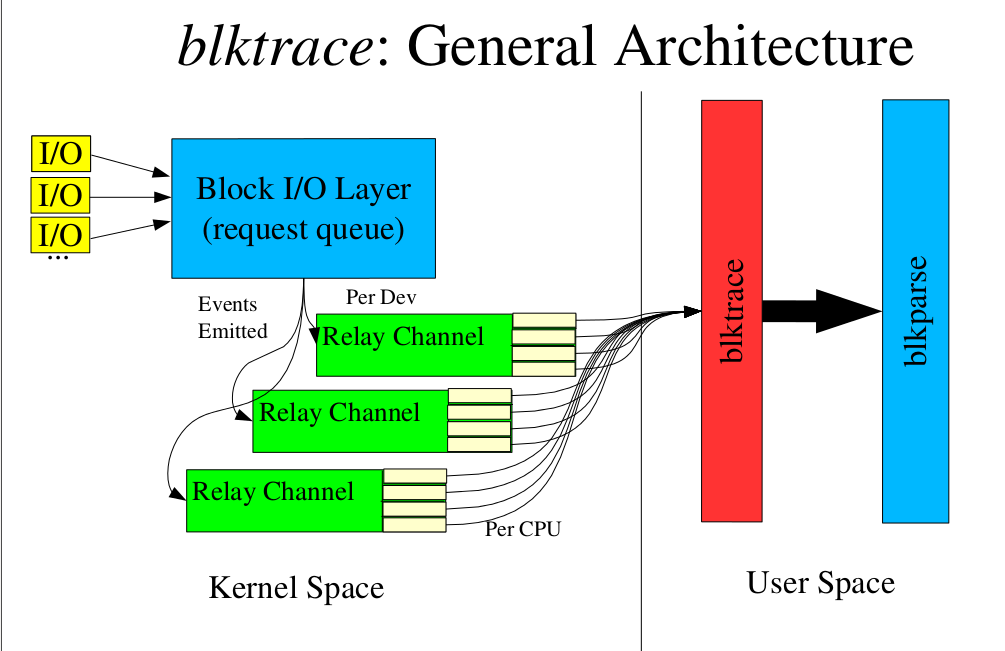
这篇讲的是Linux性能分析工具blktrace的一个隐藏用法,它能极大简化远程主机块层数据的采集流程。作者在分析远程服务器性能时,遇到了一个常规痛点:运行blktrace后,还得手动将本地生成的数据文件拷贝回来,流程繁琐且数据量大时耗时耗力。 经过一番探索,他发现blktrace其实内置了一个未公开的 `-d` 选项。通过类似 `blktrace -d /dev/sda -w 10 -d user@remote_host:/tmp/trace` 这样的命令,就能在指定时间后,直接将截取的追踪数据通过网络流式传输并保存到远程主机的指定路径中。这一功能虽然未在官方手册中广泛记载,却完美解决了远程数据采集的“最后一公里”问题。 这个发现将原本“本地采集-手动传输”的两步流程合二为一,特别适合在多台服务器上快速定位I/O瓶颈的运维和性能调优场景,是一个能立即提升工作效率的实用技巧。