初探Kafka Streams
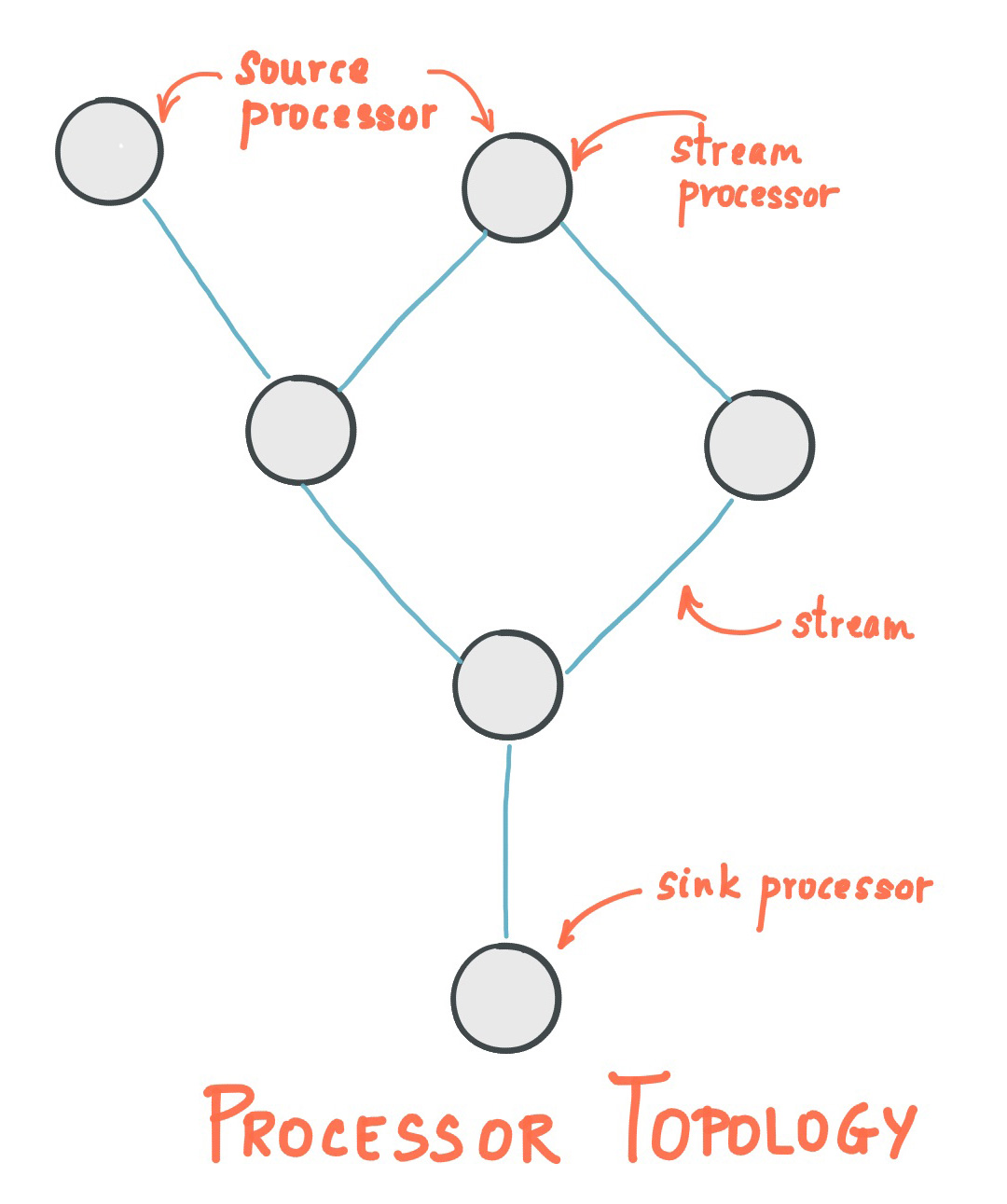
这篇文章从流式计算讲起,清晰地区分了它与批量计算及实时计算的核心差异。流式处理的是“无界”数据流,追求增量式计算与实时性,而非等待全量数据。 在此基础上,文章引出了Kafka Streams——一个轻量级的客户端类库,它让Java应用能轻松处理Kafka中的流数据。它的设计亮点非常突出:除了Kafka本身几乎没有外部依赖,却能利用Kafka的分区模型实现水平扩展和顺序保证;它通过可容错的状态存储支持复杂窗口操作,并提供从高层流式DSL到底层Processor API的完整工具链。 文章进一步深入到Kafka Streams的架构内核。它解释了以Stream(无界数据集)为核心抽象,如何通过Source、Sink等Processor节点构建出处理拓扑(Topology)。同时,也剖析了流处理中至关重要的时间模型,如事件时间与处理时间的区别。最终,文章展示了Kafka Streams如何将简洁的客户端编程与强大的服务器端集群能力结合,为构建微服务提供了一条清晰的路径。