http keepalive
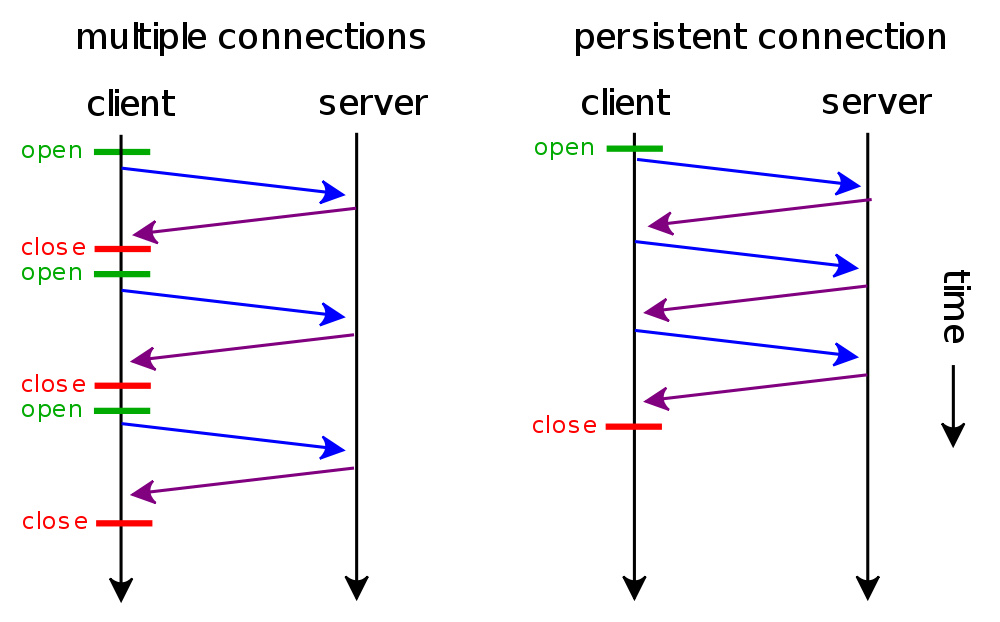
这篇讲的是HTTP KeepAlive机制的工作原理与正确配置。作者从早期每个HTTP请求都需要单独建立TCP连接的性能瓶颈出发,解释了KeepAlive如何允许在一个TCP连接上持续传输多份数据,从而显著减少连接建立开销、降低服务器内核调用与TIME_WAIT状态连接数。 不过,文章也明确指出KeepAlive并非“免费午餐”,配置不当的长连接反而会导致系统资源被无效占用,其损失可能超过重复建立连接。因此,正确设置`keepalive_timeout`参数至关重要。 作者通过编写脚本与`tcpdump`抓包,细致地分析了三种场景:关闭KeepAlive、开启KeepAlive(超时300秒)、以及在同一连接上发送多个请求(超时180秒)。测试清晰地揭示了TCP连接从建立、数据传输到最终释放的完整生命周期。一个关键发现是,`keepalive_timeout`的计时器是在最后一个HTTP响应发送完毕后才开始启动,并在每次收到新请求后重置。这意味着合理的超时设置需要在复用连接提升性能与避免资源长期占用之间取得平衡。