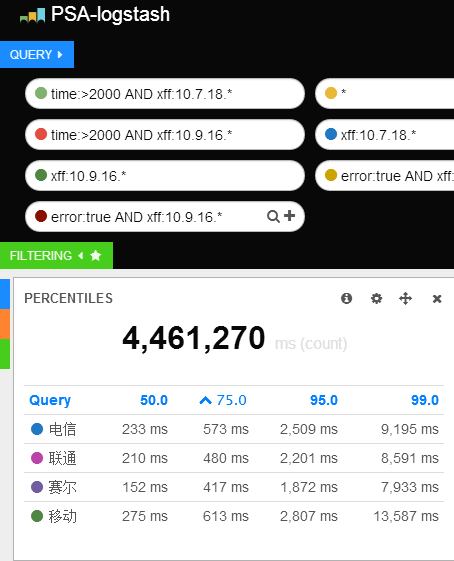
给 Kibana 实现百分比统计图表
这篇讲的是作者如何在一个下班前的冲动下,给 Kibana 3.1 手动添加 percentile 图表类型,以支持 Elasticsearch 的百分比统计功能,结果却挖出了一连串坑。 作者的初衷很直接:利用 Elasticsearch 1.1 新增的 percentile aggregation 来做更细致的日志区间分布分析,并认为这能作为学习 AngularJS 的练手项目。但实际动手后发现,计划中的“简单更新 JS 库”完全行不通。最大的坑在于 Kibana 3.1 内置的 elasticjs 库版本号标注混乱(写着 v1.1.1 实则是旧版),而新版的 elasticsearch.js 代码结构又彻底重构,不再适配 Kibana 使用的 requirejs 模块化方案。 在探索了替换整个库的复杂路径后,作者找到了一个更直接的解决方案:既然 Elasticsearch 是 RESTful 接口,那就绕过这些客户端库,直接用 AngularJS 的 $http 服务手动构建请求。不过,这个过程也撞上了 Elasticsearch 本身的限制——aggregation_name 字段不支持中文字符,迫使作者需要调整 Kibana 原有的别名生成逻辑。 最终,作者用这个看似“不太优雅”但确实有效的方法实现了功能。文章记录的这些具体踩坑细节,比如库版本号陷阱、模块加载冲突以及数据字段命名限制,对同样想在 Kibana 上做定制开发的人来说,都是很实际的参考。