Linus:利用二级指针删除单向链表
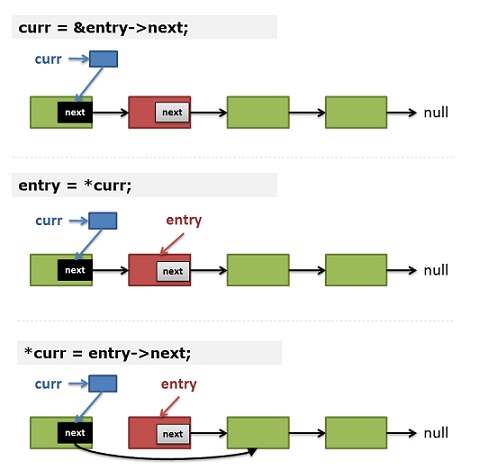
这篇讲的是Linus Torvalds如何用二级指针来优雅地删除单向链表节点。文章从Linus在slashdot上对一段“标准”代码的批评切入,他直言那种需要维护`prev`指针并判断是否为表头的写法,表明作者“不懂指针”。 核心对比了两种实现思路。传统写法(很多教科书和面试题的标准答案)需要额外维护一个`prev`指针,并在删除时判断当前节点是否为链表头,代码中存在条件分支。而Linus推崇的“core low-level coding”技巧,是直接使用一个指向节点指针的指针(即二级指针`node** curr`)来遍历和操作链表。其精妙之处在于,无论要删除的是表头还是中间节点,都可以通过统一的`*curr = entry->next`操作完成,无需任何条件判断。文章通过逐行代码解析和示意图,阐明了这种写法如何将“前驱指针”的概念融入到对`next`指针本身的间接操作中,最终生成更清晰、更可能被编译器优化出高效指令的代码。 这种对指针的深刻理解和运用,体现了Linus所看重的注重细节、追求高效底层编码的审美。