流量引导:网络世界的负载均衡解密
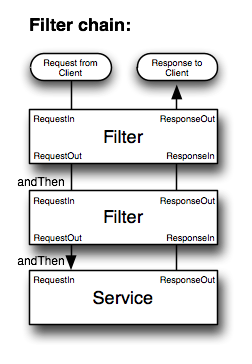
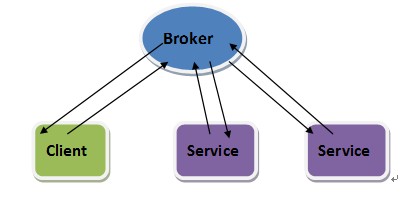
这篇讲的是大型互联网系统如何把用户流量合理分配到多台服务器上。作者从早期云计算服务商简单地将域名指向一个服务器IP出发,指出这本身并非负载均衡,进而引出高可用和扩展性带来的挑战。 文章梳理了负载均衡技术的核心演进路线。首先分析了简单DNS轮询的弊端,比如DNS缓存导致故障切换缓慢,TTL设置也令人左右为难。接着,引入了四层(L4)网络负载均衡器,通过一个虚拟IP(VIP)和基于五元组的哈希算法,快速、高效地在多台服务器间分配连接,并具备了健康检查能力。为了应对数据中心级容灾,又引入了利用BGP泛播(Anycast)将同一VIP宣告到多个站点的方案,但也面临流量控制和就近访问的难题。最终,为了支持更复杂的应用逻辑(如缓存、限速、基于Cookie的分发),七层(L7)负载均衡器被加入架构,它能解析请求内容,做出更智能的决策,但其更高的计算成本也需通过前置L4均衡器来缓解。 文章指出,负载均衡是一个随云计算不断发展的复杂课题,从L4到L7,从单站点到多站点,其演进始终围绕着高可用、灵活性和控制力的权衡。