lock free的理解
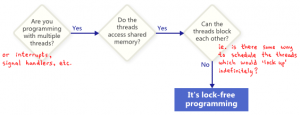
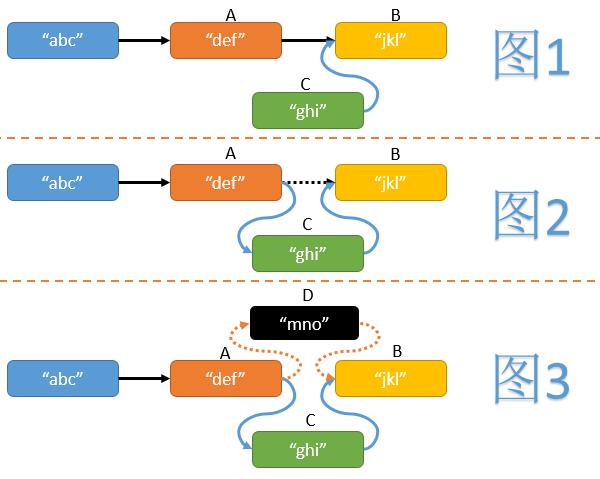
这篇文章帮读者厘清了一个常见误解:很多人以为“无锁”(lock free)就是指程序不使用互斥锁,但实际上这个概念与“用不用锁”并无直接关系。作者指出,lock free的正确定义是:程序能够保证在所有线程中,至少有一个线程可以持续推进,而不会互相阻塞。这意味着即使某个线程挂掉,整个程序的执行流依然能够向前。 文章用一个典型的无锁循环代码举例——两个线程不断交替修改同一个变量,结果却可能互相卡死,这恰恰说明“不用锁”未必就是 lock free。相反,使用锁也可能实现 lock free 的特性,关键在于设计是否保证了系统整体的进展性。 最后,作者提到在实际编码中,lock free 的实现通常依赖 CAS(Compare and Swap)这类硬件支持的原子操作,从而在避免传统锁开销的同时,保障并发安全与性能。