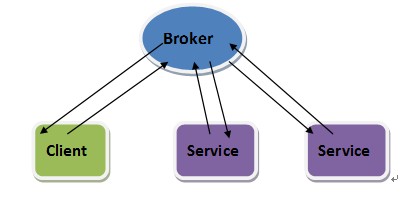
FFLIB 框架Broker 之Master/Slave 模式
这篇讲的是 FFLIB 框架中经典的 Master/Slave 架构设计。文章从分布式系统常见的节点角色与协调问题出发,详细拆解了基于 Broker 模式的 Master/Slave 实现。 核心在于,作者厘清了主(Master)从(Slave)节点各自的职责边界与协作流程——Master 负责全局的调度与状态管理,而 Slave 则专注于具体任务的执行与反馈。文中通过组件关系图,清晰地展示了这种模式下消息如何流转、状态如何同步,以及故障时如何进行主从切换。 这种架构模式直观地解决了分布式环境下的负载均衡与高可用问题,将控制逻辑与执行逻辑解耦,让系统结构更清晰。文章最后的实战分析也印证了,采用此模式的框架在稳定性和扩展性上都有不错的表现。