kmemcache源码浅析
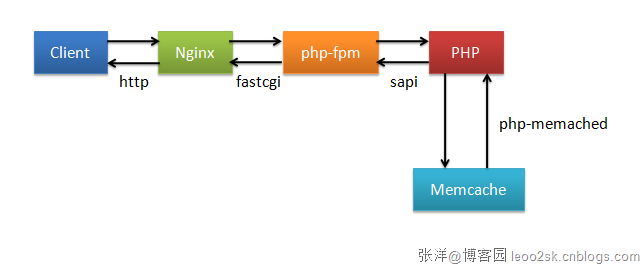
这篇讲的是memcache的Linux内核移植版kmemcache的源码实现。作者深入分析了这个不走寻常路的高性能缓存项目,重点剖析了它如何摒弃了常见的epoll通知机制,转而利用网络数据包 skb 的回调函数,实现了更细粒度的 packet 级调度。 文章的核心在于揭示kmemcache独特的网络模型设计:一个dispatcher(调度器)与多个worker(工作线程)协同工作。其中dispatcher专门负责处理TCP和Unix域套接字,并将新建的连接分配给特定的worker;而所有的UDP请求也由这些worker直接处理。 在实现细节上,文章拆解了用户态守护进程umemcached与内核模块kmemcache.ko之间,如何通过Netlink机制完成启动参数传递等关键交互。作者结合具体的代码结构(如cn_entry、cn_queue),清晰地展示了“请求-应答”的同步通信流程,以及其中涉及的序列号管理和回调处理等巧妙设计。 整体来看,这是一篇扎实的内核级源码剖析,它不仅解释了kmemcache“做了什么”,更细致地拆解了它是“怎么做到的”,对于想理解Linux内核网络子系统优化或高性能缓存实现的读者来说,提供了非常具体的参考。