JavaScript內存优化
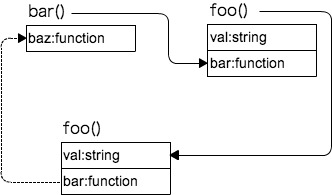
这篇讲的是JavaScript如何从语言底层进行内存优化。作者从作用域、作用域链和闭包这三个基础但关键的机制切入,解释了它们如何影响内存的分配与释放,比如未用`var`声明的变量会意外挂到全局作用域,而闭包则会延长内部变量的生命周期。 文章进一步剖析了V8引擎(Node.js和Chrome的核心)的内存回收策略,包括其分代管理思想(新生代与老生代)以及Scavenge、Mark-Sweep等主要垃圾回收算法。核心观点在于,理解“引用”是判断对象是否存活、能否被回收的根本,这直接决定了优化的方向。 最后,文章将理论落地到实践,推荐了如“善用函数作用域包裹代码”等具体优化技巧,其背后的逻辑正是利用函数作用域来及时终结不再需要的变量引用,避免内存泄漏。对于前端开发者、Node.js服务端开发者而言,理解这些原理是写出高性能、低开销代码的重要一步。