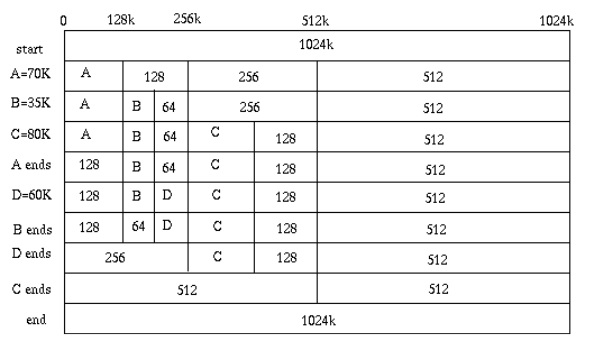
伙伴分配器的一个极简实现
这篇讲的是内存分配算法“伙伴分配器”的一个极简实现。文章从Linux内核经典的伙伴系统出发,将其核心思想抽象出来,并聚焦于GitHub上wuwenbin的一个极简版本,详细拆解了它的设计与实现。 作者将复杂的内存分配问题,巧妙转化为对一棵完全二叉树的管理。每个节点用一个数字(`longest`)标记,直接表示其对应内存块中最大连续空闲单元的大小。分配时,深度优先搜索找到合适节点并将其标记为0;释放时,则回溯并检查相邻节点,通过简单相加判断能否合并。整个过程在O(logN)时间内完成。 文章的精妙之处在于对比了另一种用四个状态(UNUSED/USED/SPLIT/FULL)管理节点的实现。极简版通过“`longest`”这一个数值,同时承载了状态和权重信息,避免了复杂的状态机和额外的条件判断,让分配、释放的逻辑变得异常清晰和优雅。这种“少即是多”的突破常规思维,正是其被称道的原因。