脚本错误量极致优化-监控上报与Script error
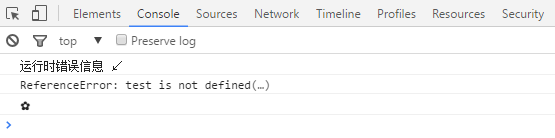
这篇讲的是前端监控中一个常见痛点:脚本错误上报后却只拿到一堆无用的“Script error.”信息,无法定位问题。作者以手Q家校群的优化实践为案例,系统梳理了从监控到上报的完整流程。 文章首先厘清了两种核心监控方式:try-catch用于捕获特定代码块的已知错误,而window.onerror则像一张大网,能捕获全局未预料的语法和运行时错误。两者结合,才能高效地构建监控体系。在信息上报环节,介绍了通过动态创建Image标签这类轻量可靠的常见做法。 但文章的重点和亮点在于深入剖析了“Script error”的成因。它揭示了当页面加载并执行跨域脚本(例如CDN上的脚本)时,出于安全策略,浏览器会阻断详细的错误信息传递,只返回一个笼统的“Script error.”。针对这一经典难题,文章指出了根本解法:需要同时在服务器端为跨域JS文件设置正确的CORS响应头,并在客户端为script标签添加crossOrigin属性,这样才能让onerror事件获得完整的错误详情。 对于前端开发者而言,这篇文章的价值在于它不仅讲清了“怎么做”,更讲透了“为什么”,提供了一套可落地的脚本错误监控最佳实践,直接助力提升线上项目的稳定性和问题排查效率。