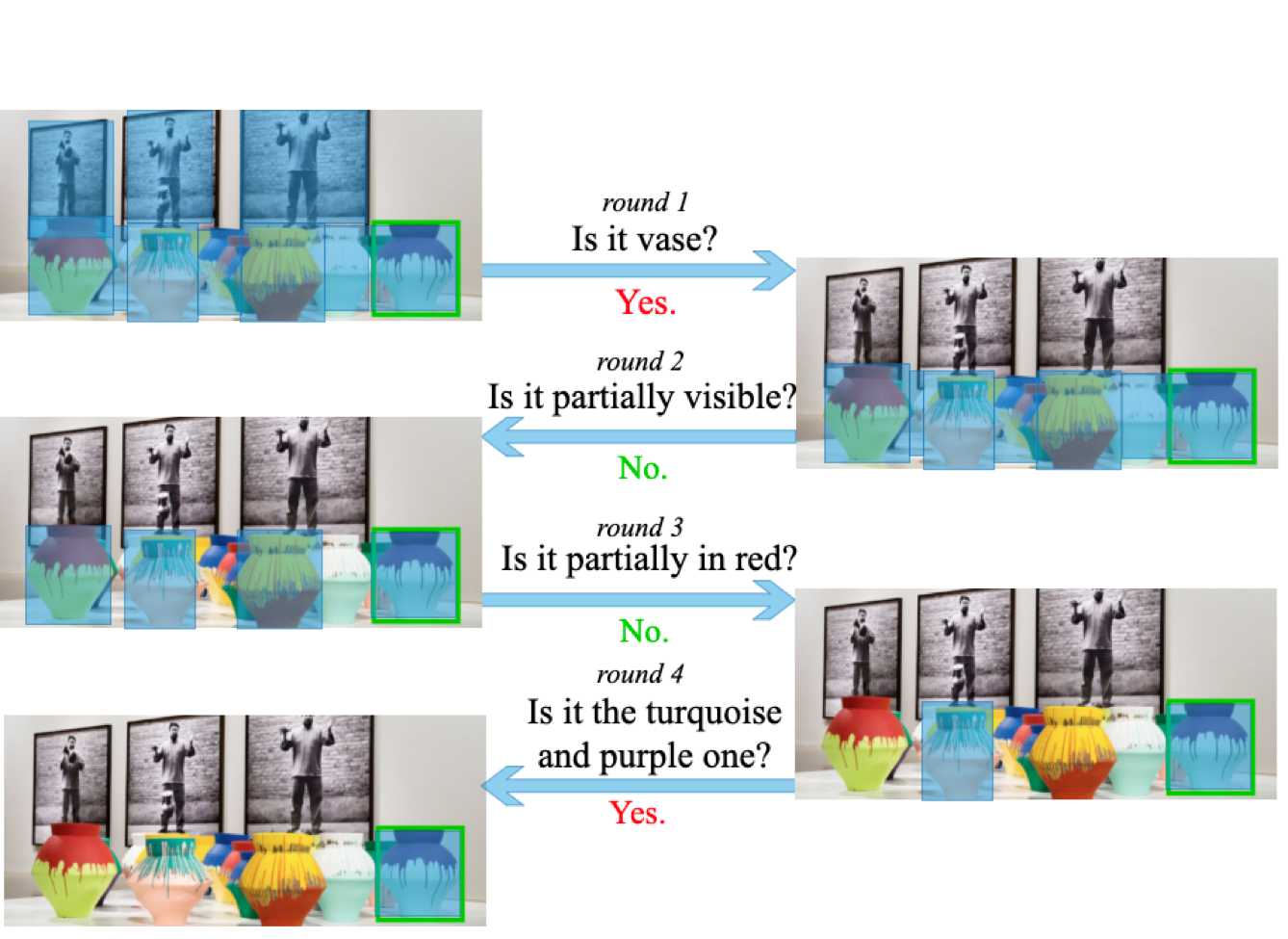
拆解Manus:真正有用的深度报告的生成
传统大模型在执行大规模分析任务时,会因上下文窗口被持续填满而导致信息压缩和质量下降,即“上下文窗口陷阱”。为解决此问题,业界探索出两条主要技术路线。其一以Google Gemini Deep Research为代表,通过升级模型、扩大上下文窗口并强化多步推理能力,适合需要深度综合分析的任务。其二以Manus Wide Research为代表,采用分布式并行架构:将大型任务拆解为多个独立子任务,由数百个具备独立上下文的子Agent并行执行,最后由主Agent汇总。这种方式从结构上规避了单Agent上下文溢出的瓶颈,确保大量独立对象(如数十家公司)分析深度的一致性。其架构借鉴了CodeAct论文思想,结合ReAct执行循环、沙箱隔离环境、有向无环图任务分解以及动态质量检测机制,模拟了人类研究员“规划-检索-分析-迭代”的完整工作流,标志着AI从聊天助手向具备规划、工具使用、迭代验证与综合能力的研究助手演进。