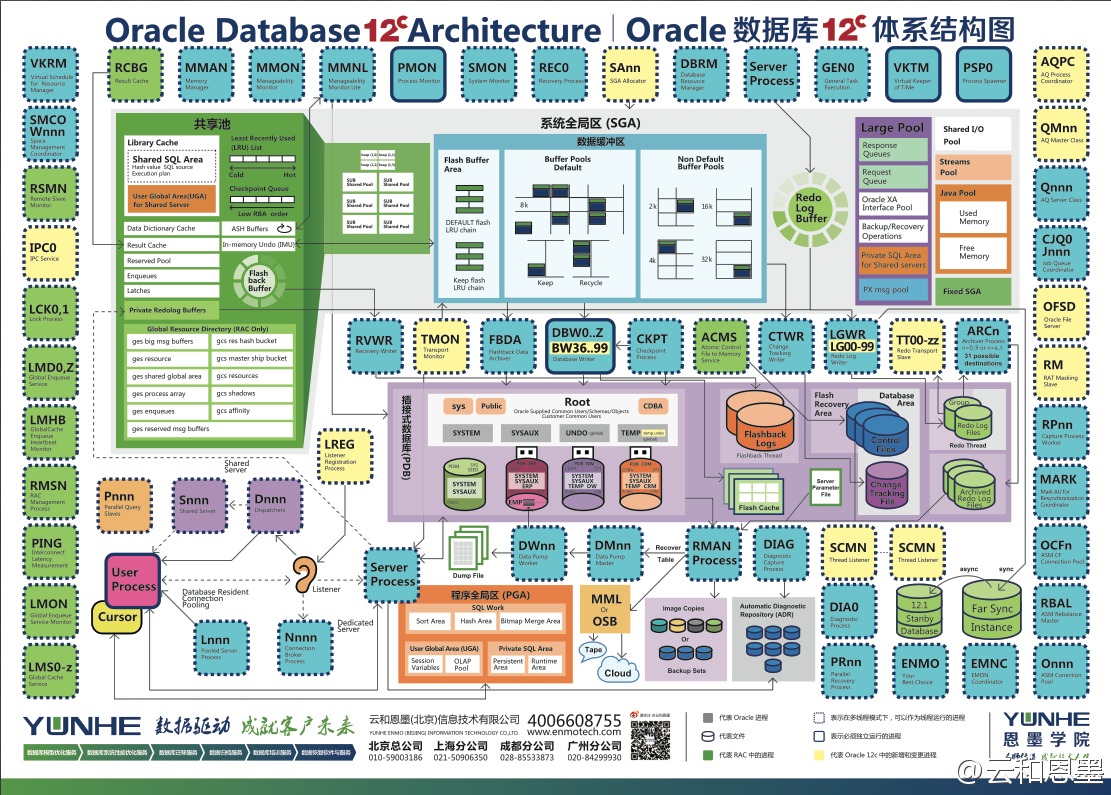
云和恩墨版Oracle Database 12c 最新体系结构图下载
这篇分享的是云和恩墨精心制作的Oracle Database 12c体系结构图。该图最早于2013年甲骨文全球大会上发布,历经多达43个版本的反复修订和打磨,旨在为技术爱好者们提供一份准确、清晰的数据库架构全景参考。其细节之处凝结了团队深厚的技术研究与精益求精的态度。 如今,这份高质量的架构图已开放电子版下载。文章直接提供了Windows版压缩包以及适配Mac不同分辨率(1280X800与1920X1080)的JPG图片下载链接,方便不同平台的用户使用。对于这样一个持续迭代的专业成果,作者也开放了反馈通道,欢迎读者指出任何可能存在的错误或问题,以便在后续版本中进行更正与完善。