按照重要程度划分数据库级别
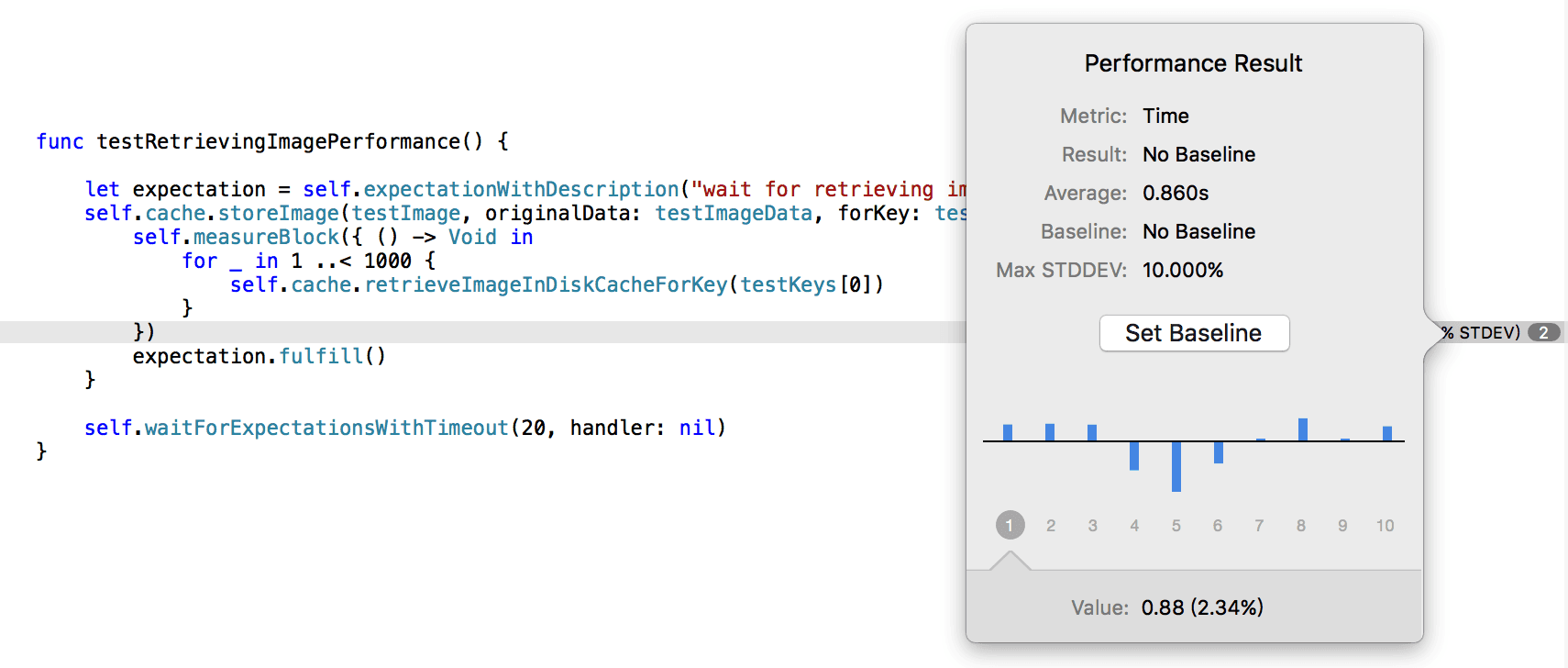
这篇讲的是一个为数据库重要性分级的实用框架。作者没有空谈理论,而是直接给出了从S级到D级的清晰划分,并为每个级别匹配了具体的业务场景、潜在影响范围以及相应的灾难恢复成本。 比如,一个仅影响几十人的测试系统(D级)与像12306这样的大型公共应用(S级),在业务类型、灾难救援价格(从几千元到50万元以上)以及需要的备份与灾备设施(从“几乎无任何有效备份”到“全冗余部署”)上,有着天壤之别。 这套体系的价值在于,它让技术团队能清晰地评估和沟通数据库资产的业务价值,并据此决定投入多少资源来保障其数据安全与业务连续性。文章用一个简洁的表格呈现了这种对应关系,对于需要制定数据保护策略的团队来说,这是一个非常直观的决策参考。