RabbitMQ与Redis队列对比
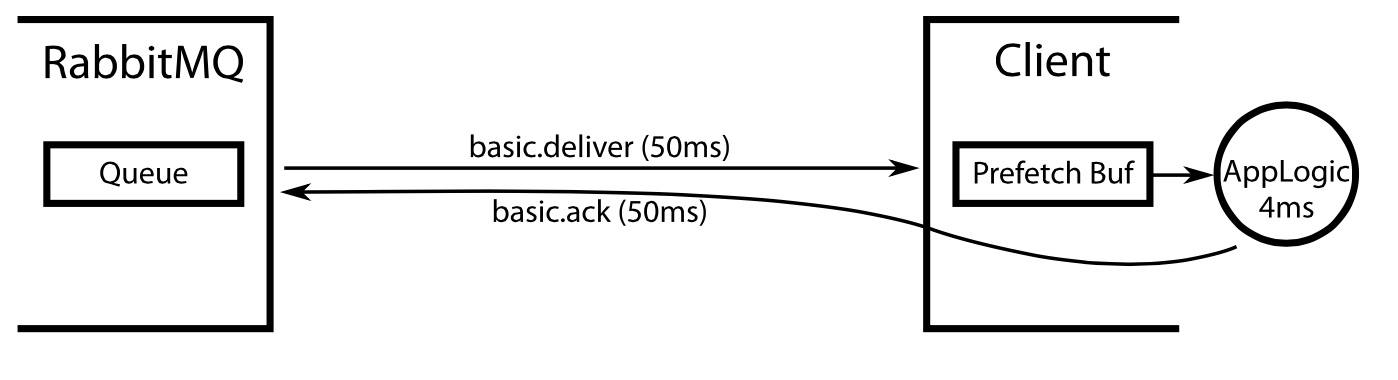
这篇技术文章聚焦于RabbitMQ与Redis作为消息队列时的核心差异。作者从可靠消费、发布确认、高可用性、持久化、负载均衡等关键维度展开对比,指出Redis在消息可靠性和系统监控方面需要较多自行实现,而RabbitMQ内置了完整的确认、持久化和监控机制。 具体来看,两者在可靠消费上差异明显:Redis消费失败可能导致消息丢失,而RabbitMQ能自动将失败消息重归队列。性能测试数据显示,在处理128Bytes到10K的不同数据体量时,两者出入队性能各有特点。文章最终提炼出适用场景:Redis更适合轻量级、高并发的即时计算或缓存场景,例如秒杀计数器;RabbitMQ则更适用于需要保证消息可靠传递的批量异步处理或任务负载均衡。 文章并未给出绝对结论,而是强调最终选择需结合系统对可靠性、监控能力和实际负载的具体要求来综合权衡。