第六章:分区
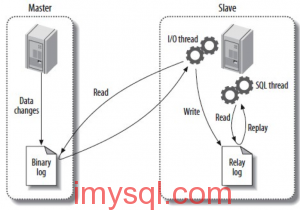
传统主备复制架构存在扩展性瓶颈、单点故障和数据隔离等问题。为应对这些挑战,系统扩展分为垂直扩展与水平扩展。垂直扩展通过升级单机硬件实现,具有简单、一致性高的优点,但受限于物理上限且存在单点故障。水平扩展则通过增加服务器集群节点来分担负载,具备理论上的无限扩展性、高可用性和弹性伸缩能力,但引入了架构复杂性、数据一致性挑战及网络延迟等新问题。 因此,分布式系统常采用水平扩展中的“分区”策略,即将数据分摊到多个节点上,而非由所有节点存储全量数据。分区通常与复制技术结合,在保障数据分片的同时通过多副本提升容错性。引入分区后,系统需解决数据请求如何路由到正确分区、分区数据再平衡以及全排序操作支持等新挑战。后续内容将进一步探讨具体的分区策略、请求路由机制以及分区热点问题。