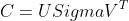谈谈SVD和LSA
这篇讲的是SVD(奇异值分解)和LSA(隐含语义分析)之间的关系。作者首先拆解了LSA的核心思想:它是一种主题模型,认为词语背后由潜在主题驱动。比如“计算机”和“电脑”在传统词向量空间中无关,但在LSA看来它们同属一个主题,因此包含它们的文章也相关,这突破了表面词汇的限制。 而SVD正是实现LSA的关键数学工具。文章从特征值与特征向量这些基础概念切入,为理解SVD如何分解文档-词矩阵、提取潜在语义结构做了铺垫。作者也点出SVD的广泛应用,比如它同样是PCA(主成分分析)和图像压缩的技术基础。整篇文章从数学基础讲到实际应用,清晰地勾勒出SVD作为通用分解方法,如何催生了LSA这一文本分析利器。