一种以ID特征为依据的数据分片(Sharding)策略
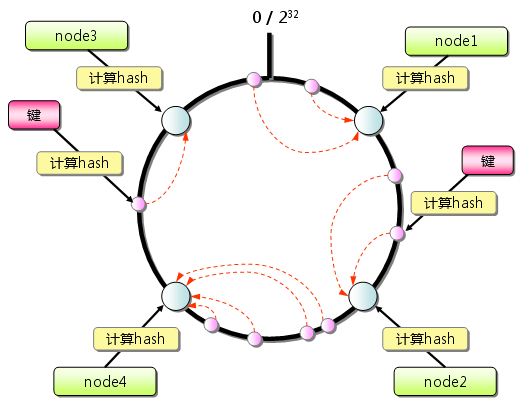
这篇讲的是在分布式系统中如何给数据做分片。作者从一个具体痛点出发:用雪花算法生成的ID虽然全局唯一,但它们自带时间属性。如果简单地按ID范围或时间范围做分库分表,很容易导致数据分布不均,最新的请求和数据会集中打在同一个分片上,形成热点。 文章提出的核心策略是“以ID特征为依据”。它深入分析了雪花ID的二进制结构——其中包含了时间位、自增位和机器位。方案的关键思路不是直接利用时间位,而是巧妙地利用了每台机器在毫秒内生成的自增序列位。通过对ID进行位运算或取模,将数据相对均匀地分散到各个分片中。这样即使ID有时间趋势,实际的写入压力也能被有效打散。 这种策略的结论很直接:它在不引入复杂路由算法的前提下,实现了数据的均匀分布,有效避免了热点问题,同时保留了ID本身的有序性。对于使用雪花ID且面临分片压力的系统,这提供了一种直接、高效的优化思路。