Hacker News 排名算法工作原理
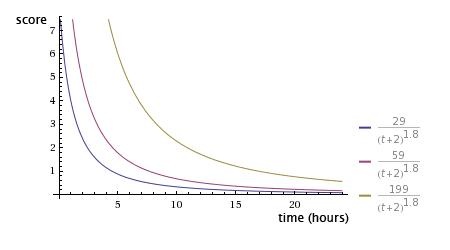
这篇深入剖析了Hacker News标志性的排名算法。作者从HN开源代码中提取出核心公式:得分 = (投票数-1) / (提交时间+2)^比重。这个简洁的公式,通过“比重”参数G(默认值1.8)巧妙地平衡了热门内容和时效性——G越大,老内容得分衰减越快,新文章越容易获得曝光。 文章不仅解读了公式,还通过Wolfram Alpha绘制的曲线图,直观展示了时间T和比重G如何影响分数衰减。它进一步揭示了算法中针对不同类型内容(如无链接帖子、轻量级内容)的系数调整,以及如何用Python几行代码实现它。最后,文章还附上了Paul Graham公布的、更为复杂的修正版算法,展示了实际工程中的权衡。 这篇文章的价值在于,它拆解了一个看似简单却极其有效的排名系统,揭示了如何用数学方法同时解决内容冷启动和热度衰减这两个社区产品的核心难题,对任何想构建内容推荐或排序系统的人都有直接的启发。