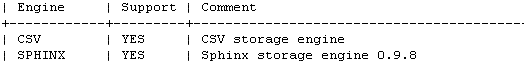程序员如何写出一份好的文档?
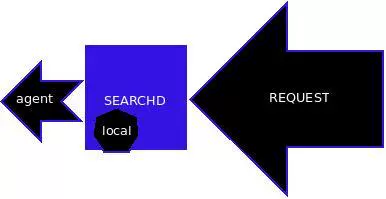
程序员的工作不止是写代码,文档质量同样影响项目协作效率。这篇经验分享文章直接切入痛点,从四个实用技巧出发,教你如何写出清晰、易懂的技术文档。 作者首先强调了结构化的重要性——杂糅的信息会变成“云里雾里”,而将功能点逐条列出,逻辑立刻清晰。其次,对于socket通信这类流程性内容,一张流程图比大段文字更直观,读者能迅速把握整体逻辑。第三,当涉及连续的数据对比(如每月bug修复量)时,用图表替代文字描述,数字变化一目了然。最后,避免直接堆砌代码,转而使用伪代码或流程图来说明设计思想,能显著降低阅读门槛,让文档更具普适性。 这些技巧的核心,正如文中引用爱因斯坦的话,都指向一个原则:简单就是美。好的技术文档也应如此,用最直接的方式传递信息,让读者轻松理解复杂的内容。