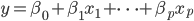数据分析中位数的应用
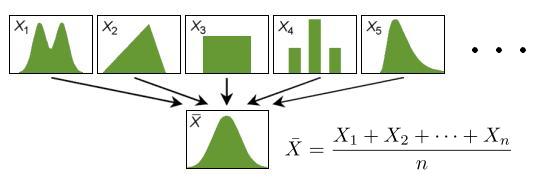
这篇讲的是如何让枯燥的折线图更直观地传达信息。作者发现,普通折线图常常无法突出数据中的关键点,于是通过对比两张图(A图是常规折线,B图则将最高的几个数据点用特殊图标标出),直观地展示了“一目了然”的视觉效果差异。 核心问题随之而来:如何从一堆数据里,自动找出那个用于区分“特殊点”与“普通点”的分界线呢?文章对比了两种常见方法——平均数和中位数。作者指出,平均数虽然反映整体水平,但极易被一两个极端的高值或低值“带偏”,无法稳定代表“大多数”情况。相比之下,中位数是把数据排序后取中间的那个数(或两个数的平均),它不受极端值影响,更能代表数据的“中间”或“典型”水平,因此成为构建这个分界线的更优选择。 为了便于实践,作者还提供了一个计算中位数的PHP函数代码示例。整篇文章从一个可视化的痛点切入,落到具体的统计概念辨析和算法实现,思路清晰,具有不错的实操参考价值。