网络栈内存不足引发进程挂起问题
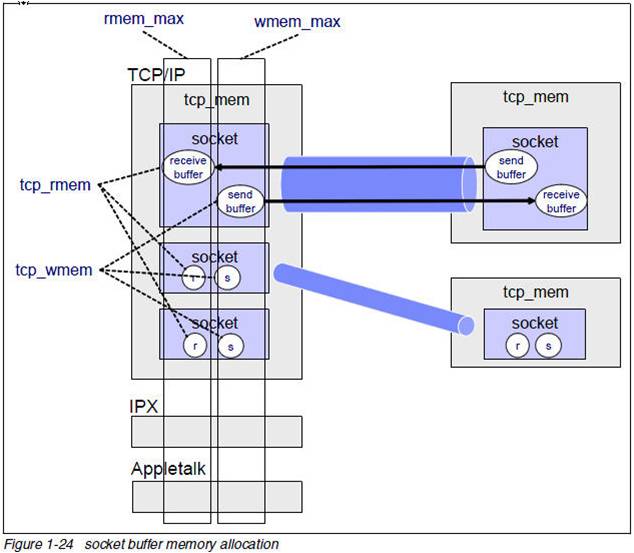
这篇讲的是高并发场景下,一个隐蔽但影响巨大的“坑”:当服务器需要支撑C1M(百万)级别连接时,TCP服务可能出现超时,甚至高达100ms的延迟。 问题的根源往往在于Linux内核的网络栈内存。文章开篇就点明,TCP的发送和接收缓冲区并非“想设多大就多大”,它们受到一系列sysctl参数(如net.ipv4.tcp_mem)的全局控制。这些内存是不可交换的物理内存,用一点少一点,系统默认值通常偏保守。在连接数暴涨时,可供分配的内存很快耗尽。 一旦内存不足,进程向socket写入数据时,内核就会将其挂起(阻塞),并调用 `sk_stream_wait_memory` 函数等待内存释放。文章直接展示了如何用SystemTap脚本精准定位这一过程——脚本输出会清晰地显示进程“blocked on full send buffer”和“recovered”的时间点,这就是导致应用层超时的直接证据。 最后,文章给出了行动指南:如果观测到了这种内存等待,就需要着手调整协议栈的内存限制参数。它通过一个具体的案例强调,面对复杂的网络问题,定量的工具与分析比猜测更可靠。