为 MySQL 增加 HTTP/REST 客户端:MySQL UDF 函数 mysql-udf-http 1.0 发布
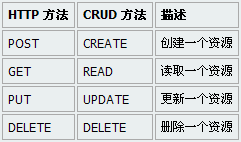
对于需要频繁与外部 Web 服务交互的数据库应用,传统的做法往往需要应用层作为中转,流程繁琐且效率不高。这篇讲的是一个能直接在 MySQL 内部解决问题的实用工具——mysql-udf-http 1.0 的发布。 作者张宴开发了这个 MySQL 用户自定义函数(UDF),核心思路是让数据库本身具备发起 HTTP 请求的能力。它提供了 `http_get()`、`http_post()`、`http_put()` 和 `http_delete()` 四个函数,覆盖了 RESTful API 的主要操作类型。这意味着你可以直接在 SQL 语句中调用这些函数,去请求或推送数据到外部服务。 目前项目支持 Linux 系统以及 MySQL 5.1.x 和 5.5.x 版本。这个工具将 HTTP 能力下沉到数据库层面,对于一些需要在数据库事务中直接同步外部状态的场景,或者构建轻量级数据库触发器应用来说,省去了应用层中转的麻烦,提供了一种更直接的技术选择。