10分钟看懂!基于Zookeeper的分布式锁
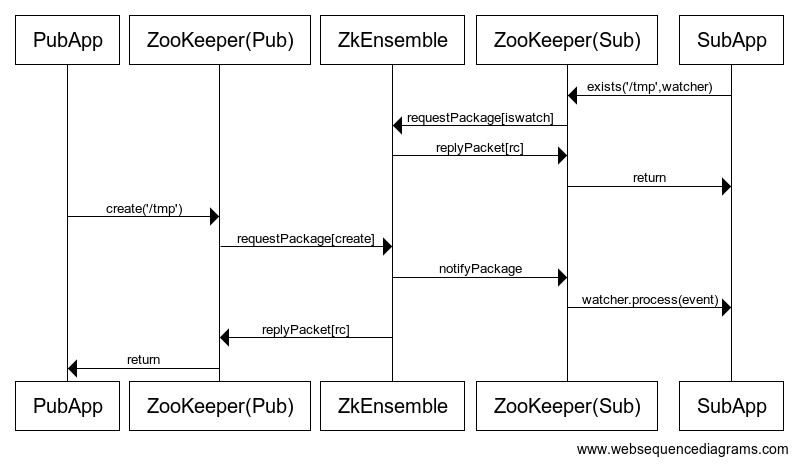
这篇讲的是如何用Zookeeper实现一个可靠的分布式锁。 作者从分布式系统协调的核心需求——分布式锁出发,直接对比了常见的数据库、Redis与Zookeeper三种方案,重点聚焦在Zookeeper的实现上。文章首先通俗地解释了Zookeeper是什么:一个提供配置管理、分布式协同等底层服务的中心化框架,其核心是一个类似文件系统的、保存在内存中的有序树状结构。 实现分布式锁的核心思路巧妙地利用了Zookeeper的几个关键特性:**有序节点**来排队,**临时节点**来防止客户端宕机导致的死锁,以及**事件监听**来高效地通知锁的释放。基本的算法是:客户端在指定根路径下创建临时有序子节点,序号最小的获得锁;否则就监听前一个节点的删除事件,从而实现公平的等待队列。 文章还深入讨论了两个关键优化。一是如何避免“羊群效应”,即每个客户端只监听自己前一个节点,而不是所有节点变更,这大大提升了性能。二是分析了Curator这个开源库如何将这些复杂逻辑封装成简单的 `acquire()` 和 `release()` API,让开发者能轻松使用。 总的来说,这篇文章没有停留在理论,而是深入到了算法细节与源码实现,把Zookeeper利用临时有序节点解决分布式锁的精髓讲得清晰透彻。