有趣的JavaScript原生数组函数
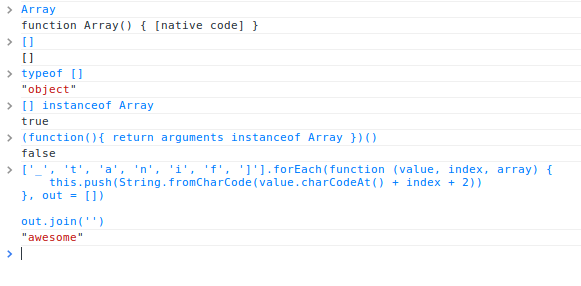
这篇讲的是 JavaScript 中那些原生数组方法的深度探索与趣味应用。文章没有停留在基础的 `for` 循环,而是系统梳理了数组原型上一系列强大而实用的方法。作者从数组创建的基本概念(如 `typeof` 返回 “object” 与 `instanceof Array` 的区别)切入,为后续理解铺平了道路。 接下来,文章像一份精选菜单,逐一剖析了每个方法的用途和细微差别。你不仅能复习 `forEach`、`map`、`filter` 这些循环与转换利器,还能深入理解 `some` 与 `every` 在条件判断上的逻辑分野。对于像 `join`(字符串化)与 `concat`(合并)这样容易混淆的操作,文章厘清了它们的核心差异。同时,它涵盖了模拟栈与队列操作的 `pop`、`push`、`shift`、`unshift`,用于数据规约的 `reduce`,以及负责元素增删查改的 `slice`、`splice` 和 `indexOf`。甚至 `in` 操作符与 `reverse` 这类小工具也被纳入讨论范围。 这不仅仅是一份 API 列表。作者将每个方法置于实际场景中,探讨了它们如何让数据处理变得更简洁、更声明式。如果你想跳出死记硬背,真正理解这些内置函数如何提升代码的优雅度与执行效率,这篇文章提供了一个扎实且有趣的视角,建议你在阅读后打开浏览器控制台亲手试试。