通过blktrace, debugfs分析磁盘IO
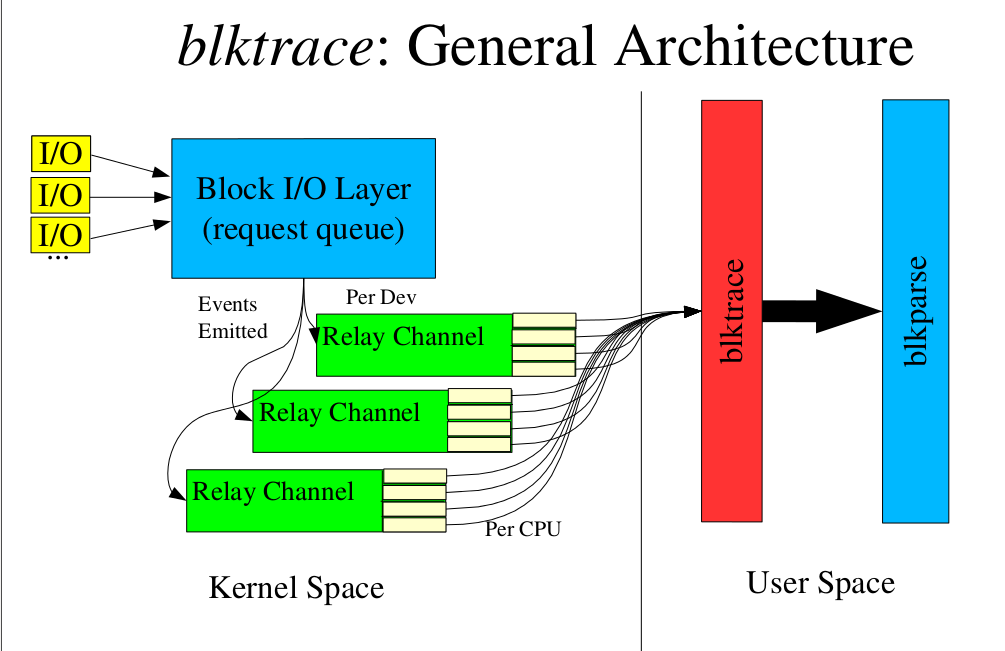
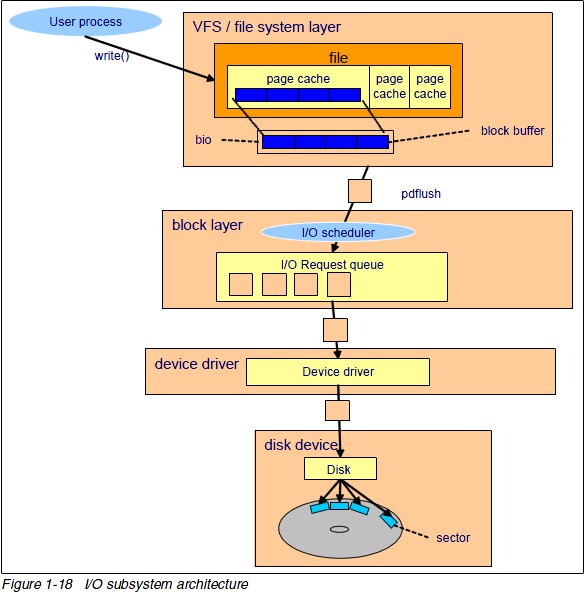
这篇讲的是当磁盘利用率飙到100%、程序变卡时,如何揪出背后的“元凶”文件。作者从实际场景出发,演示了如何组合使用blktrace和debugfs这两个工具,层层追查IO的来源。 具体来说,当iostat显示磁盘压力巨大时,先用blktrace捕获块设备层的IO请求。关键点在于grep出以“A”开头的日志行,这里是原始请求的入口,能清晰看到读写操作对应的源设备扇区。接着,通过debugfs的“icheck”命令,根据扇区号换算出的文件系统块号,反查到对应的inode号。最后,用“ncheck”命令把这个inode号映射为具体的文件路径——比如例子中的“test_file”。 整个流程就像顺藤摸瓜:从设备层的扇区,到文件系统的块和inode,最终定位到用户可见的文件。拿到这个结果后,就能结合自己的应用程序,分析为什么这个文件会被频繁读写,从而进行优化。文章给出了完整的命令示例和输出解读,实操性很强。