对话任务中的“语言-视觉”信息融合研究
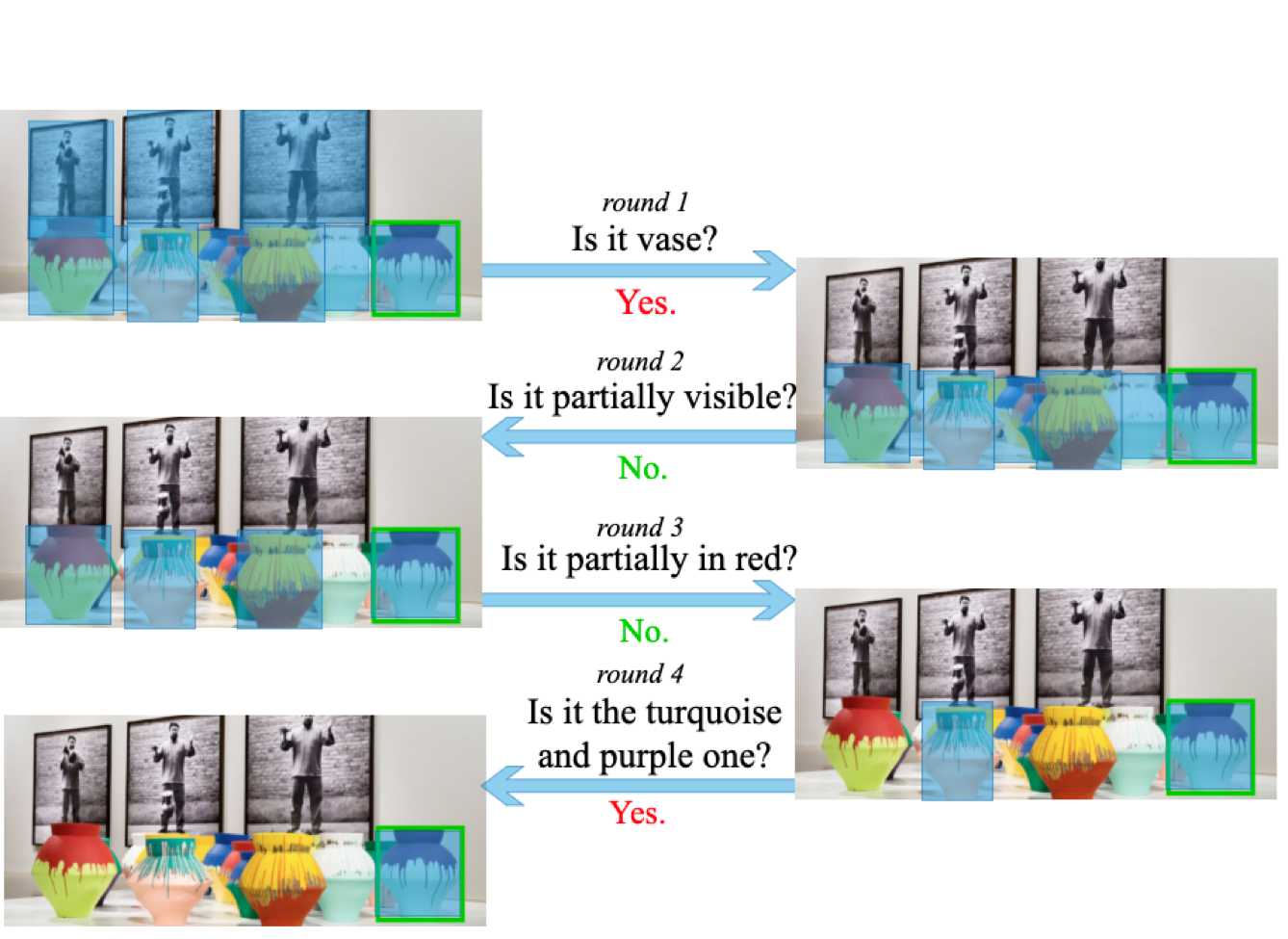
这篇讲的是如何让AI在视觉对话中更“会看眼色”。研究者们针对“目标导向的视觉对话”任务发现,现有模型有个明显短板:对话中的回答(比如“是”或“不是”)对视觉注意力的引导作用太弱。当回答改变时,AI的目光焦点本该相应转移,但旧方法往往只是简单地拼接语言和图像特征,没能突出这种动态调整。 为此,北京邮电大学与美团AI团队合作提出了一个“响应驱动的视觉状态估计器”(ADVSE)。这个模型的核心在于两个新机制:一个是“答案驱动的注意力更新”,它能根据当前回答是肯定还是否定,来决定是聚焦当前物体还是转移目光搜索新目标;另一个是“条件视觉信息融合”,可以自适应地混合图像的全局信息和差异信息。这使得模型能像人一样,根据对话进展灵活调整“看图”的策略。 在国际通用的GuessWhat?!数据集上,这个ADVSE模型在问题生成和回答任务上都取得了当时的最佳成绩。它让机器在需要通过多轮对话寻找目标物体(比如从一堆物品里找出某个)时,对话策略更有效率,也为智能助手或交互机器人等应用提供了更扎实的技术基础。