如何计算两个文档的相似度(二)
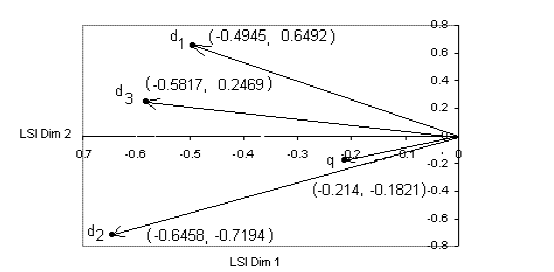
这篇系列文章的第二部分聚焦于gensim的实战上手。作者从安装这个看似简单的步骤切入,详细记录了在Ubuntu和Mac OS上配置gensim及其依赖库NumPy、SciPy时遇到的典型问题——比如Mac上因缺失Fortran编译器导致的SciPy安装失败,并给出了解决方案(通过Homebrew安装gfortran),这对国内开发者很有参考价值。 在核心的使用演示部分,文章没有照搬官方教程,而是另辟蹊径,使用了“Latent Semantic Indexing (LSI) A Fast Track Tutorial”中的三个简短英文文档作为案例。整个流程清晰展示了从文本预处理(小写化)、构建词袋字典、生成文档向量,到训练TF-IDF模型,最终通过LSI(潜在语义分析)将文档映射到二维主题空间的全过程。作者特别指出了gensim在计算IDF时未对出现频率为100%的词(如介词a, in, of)进行平滑处理导致其权重为零的现象,并以此反向论证了TF-IDF算法在过滤停用词上的有效性。 通过这个从安装到模型输出的完整闭环,文章为读者提供了一份可复现的gensim入门实践指南,为后续在“课程图谱”上的应用打下了基础。