linux异步IO编程实例分析
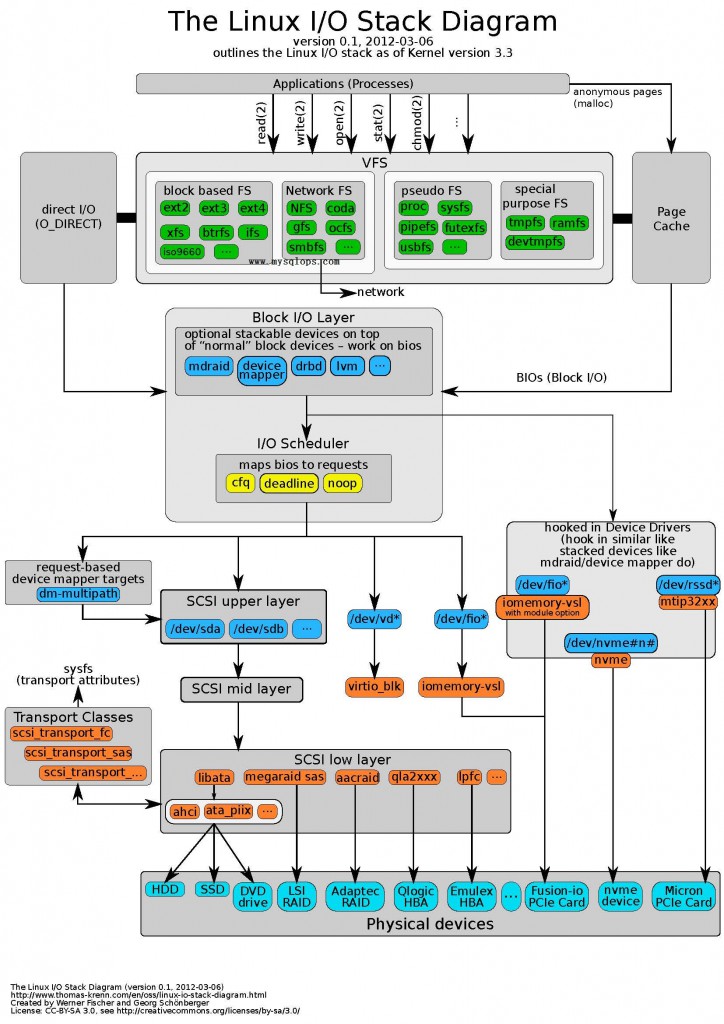
这篇讲的是Linux Native AIO(异步IO)在Direct IO场景下的编程实例。作者从Direct IO绕过系统页缓存、直接与磁盘交互的特点出发,点明了在这种模式下引入异步机制的必要性——因为同步IO模型会因等待磁盘操作而导致线程阻塞,影响性能。 文章核心在于对比,它揭示了异步IO与传统同步IO在处理磁盘请求时的关键差异:同步模型下应用线程必须等待IO完成,而异步模型允许内核在后台处理数据传输,应用则能立即继续执行或处理其他任务。这种机制在需要高吞吐、低延迟的数据库或存储系统中尤为适用。 作者进一步将聚焦于Linux Native AIO的具体实现,分析其编程接口与内核工作原理。内容不仅解释了“为何需要”,更深入到“如何实现”,通过实例探讨了如何配置和使用AIO接口来真正提升磁盘访问的并发性能,避免了同步调用带来的瓶颈。