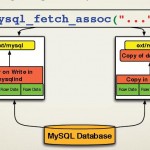
PHP最佳实践:MySQL的连接
这篇讲的是PHP开发者面临的经典选择:当老式的`mysql_*`函数在PHP 5.5后被官方废弃,且存在SQL注入等安全与功能瓶颈时,该如何正确连接MySQL数据库。 文章的核心对比非常清晰。它首先点出`mysql_*`函数的历史局限——基于过时的MySQL 3.23开发,无法支持现代特性。然后,作者将笔墨集中在现代解决方案`PDO_MySQL`上,并详细阐述了它如何解决旧方案的痛点。具体来说,`PDO`通过支持预处理语句,在提升重复查询性能的同时,从根本上防御了SQL注入攻击。它还为事务管理提供了可靠接口,这对于保证数据一致性至关重要。 文章并未止步于此,还深入介绍了存储过程、异步查询等进阶数据库交互方式,并分析了各自的优缺点与适用场景。最后,作者明确指出,切换到`PDO`或`mysqli`扩展不仅是技术趋势,更是保障应用安全与性能的必要升级。整个行文逻辑是从“为何淘汰旧事物”到“新事物如何更好”,给出了明确的迁移指引和原理剖析。