尝试mysqlbinlog的flashback功能
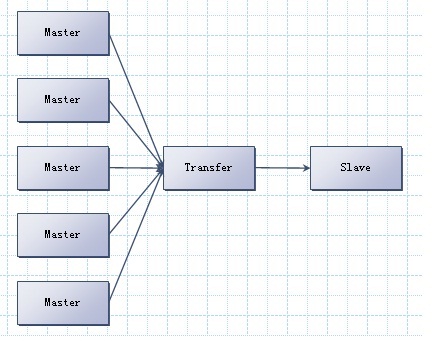
这篇文章讲述了作者在实际项目中如何利用 mysqlbinlog 的 flashback 功能,实现对误操作数据的快速回滚。作者首先分享了在业务高峰期一次不慎的 DELETE 操作带来的风险,随后深入介绍了 flashback 功能的原理——它通过逆向解析 binlog,生成与原操作相反的 DML 语句,从而精准撤销错误操作。 文章不仅演示了具体的命令与参数配置,还对比了该功能与传统备份恢复方案的效率差异,特别强调了其在时间窗口和数据一致性上的优势。作者通过回滚一个包含数万行数据的表,验证了功能的有效性,并总结了适用场景与潜在限制。对于数据库运维人员而言,这篇实践分享提供了一个直接可用的数据恢复思路。