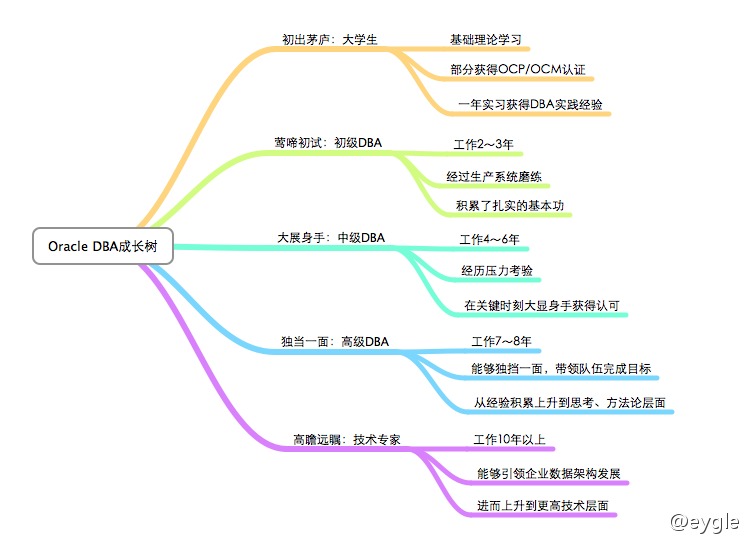
PL/SQL的那些事儿
这篇讲的是PL/SQL在Oracle数据库中的正确使用姿势,作者通过对比两种常见场景,点明了优化的核心。 文章清晰地划分了PL/SQL的两类使用场景:一类是作为“胶水”,串联一系列SQL分析语句,性能瓶颈主要在SQL引擎;另一类是用游标逐行处理数据,进行过程化计算。作者指出一个关键现象:即便优化后者,性能提升也有限;但若将其重写为前者纯SQL驱动的模式,性能常能获得成百上千倍的提升。这揭示的根本原则是:务必优先利用数据库核心的SQL引擎能力,而非用过程化代码(无论是Java还是PL/SQL)去替代它。 当然,PL/SQL并非一无是处。文章也强调了其不可替代的价值,例如实现数据库内部监控工具。作者用了一个形象的类比:将监控代码部署在数据库内部,就像把监控脚本直接放在被监控主机上,避免了网络开销,能获取更精确的数据。文中推荐的工具Session Snapper,就是一个典型的、高效运行在数据库内部的PL/SQL诊断范例。 因此,PL/SQL是一把宝剑,用于数据库管理与扩展时锋利无比;但若当作处理数据的“菜刀”来过度使用,则可能事倍功半。