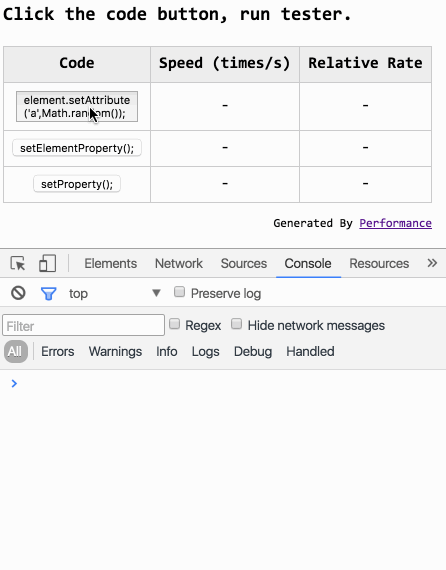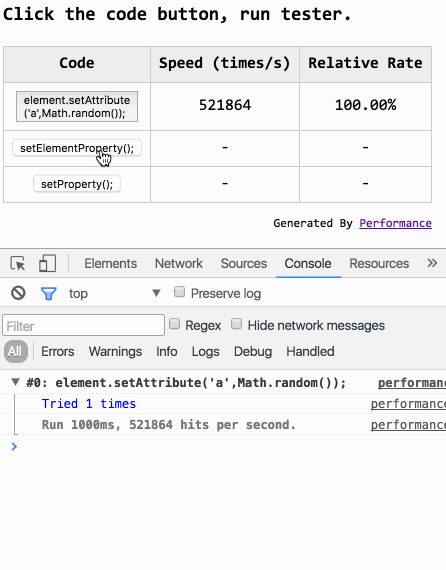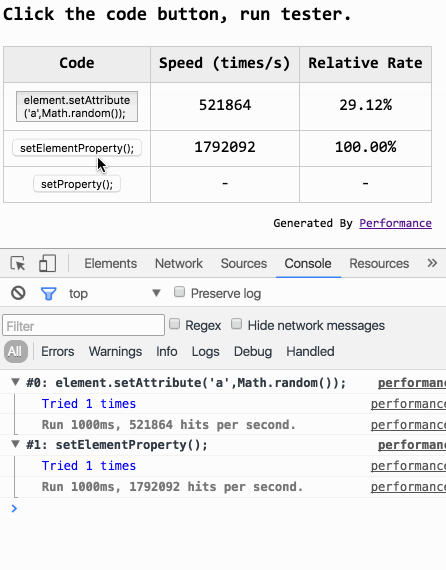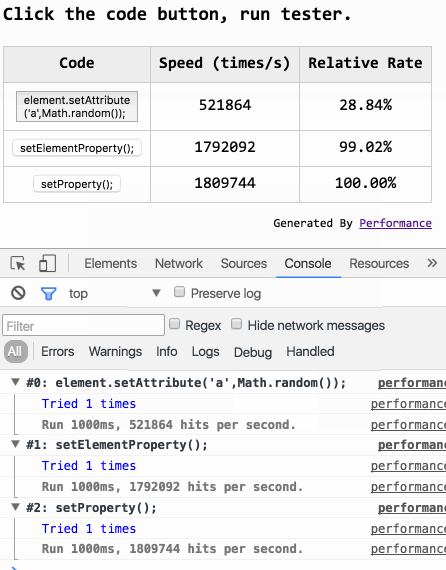
「置顶」我做了什么
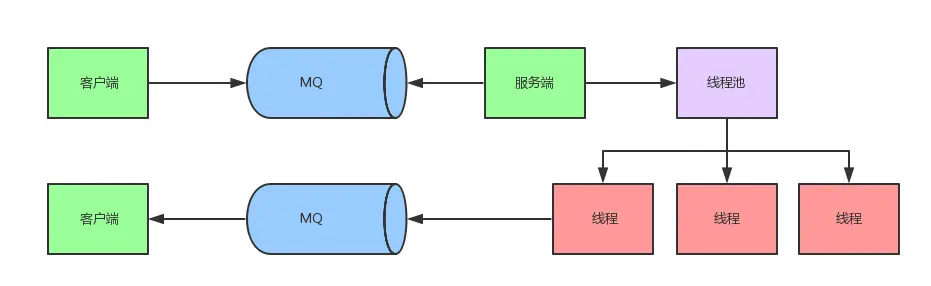
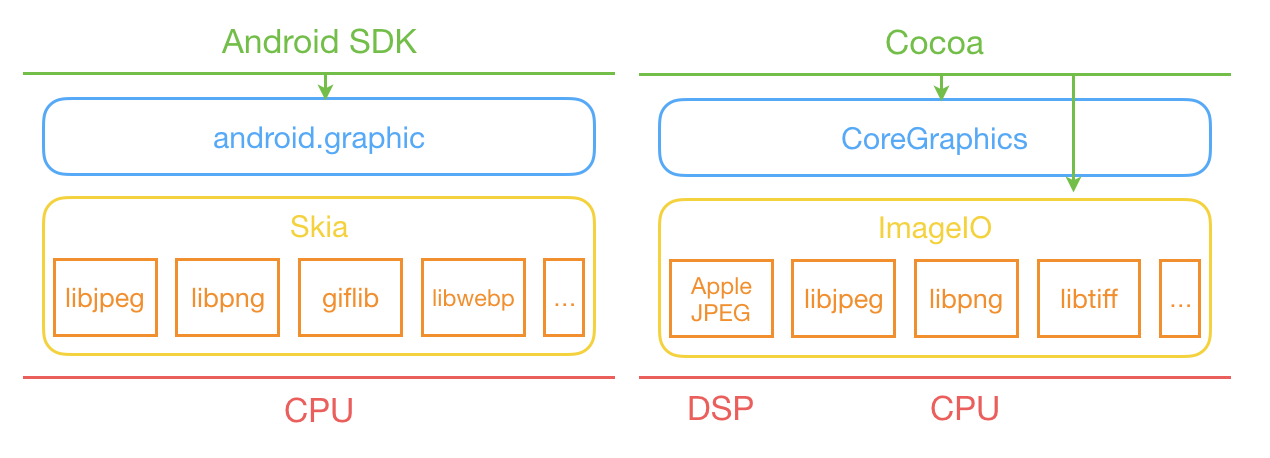
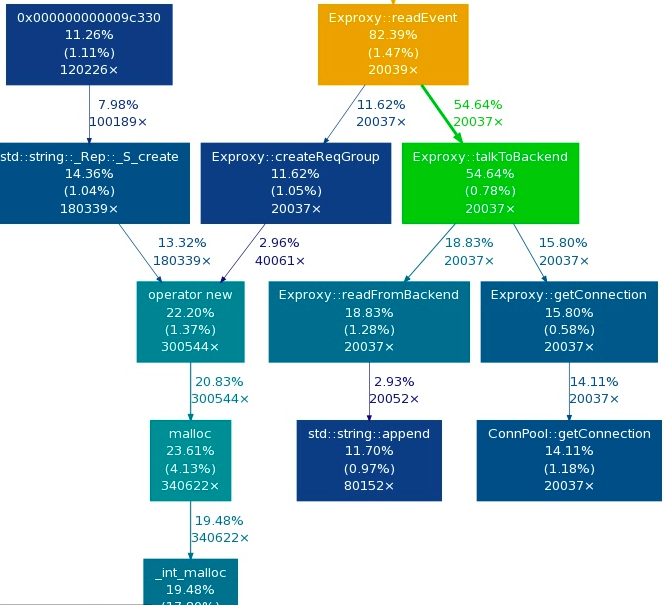
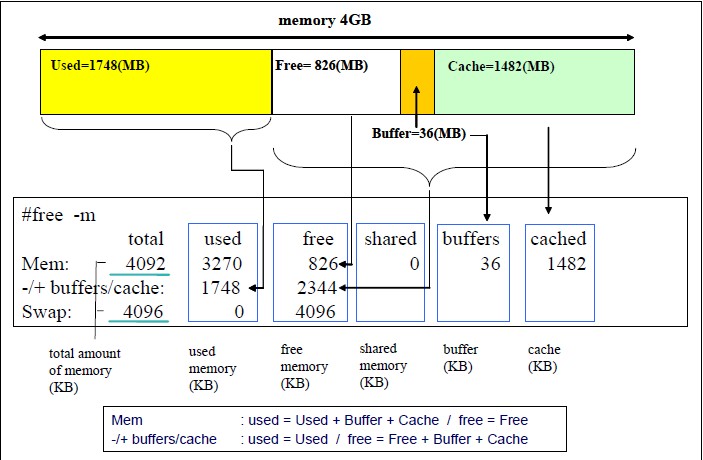
本文是作者的个人技术项目总览,系统梳理了他长期维护的四大方向工作。在 Android 性能分析与工具链建设上,以 SmartPerfetto 为核心,构建了一套基于 Perfetto 的 AI 辅助分析体系,并配套开发了 Android App Memory Analysis、TraceFix(自动插桩)等专用工具,形成了从 Trace 采集、数据可视化到自动化分析的完整流程。AI 与自动化方向,重点介绍了本地运行的 OpenClaw 系统,它整合了多种模型与工具,用于知识管理、日报生成及工程协作,其公开成果如 AI Field Notes 展现了持续的自动化信息处理能力。此外,作者还开发了数款面向真实需求的 iOS 与 Android 应用,如健康预测 App 100Years。在技术内容输出方面,他通过维护 Android Performance 博客、Android Weekly 周刊及知识星球,沉淀了大量关于系统性能、工具使用及方法论的深度文章与案例,构成了公开的知识体系。整体而言,这些项目贯穿了从底层性能分析、工具开发、AI 实践到应用实现与知识分享的完整技术闭环。