淘宝用户增长的5+1个策略
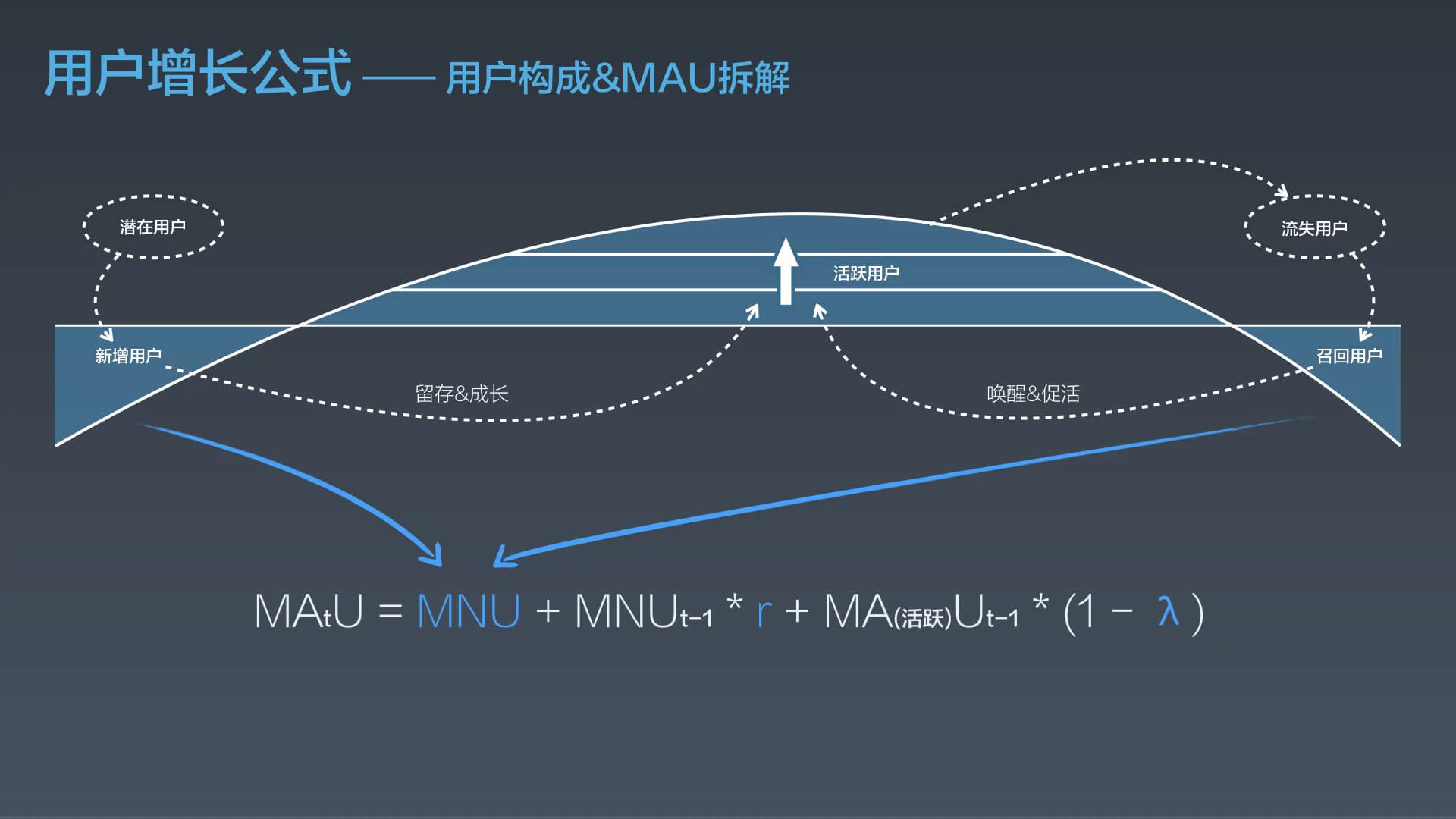
这篇讲的是淘宝如何拆解和制定用户增长策略。作者没有陷入实现细节,而是从平台视角出发,首先构建了一个清晰的用户增长公式:MAU由上月留存、未流失用户以及本月新增(MNU)构成。增长抓手的核心,就聚焦在MNU的引入上。 围绕MNU引入,文章分享了淘宝的流量引入体系——一个“三纵两横”的架构。具体策略上,智能投放的核心是“对人”和“对素材”的深刻理解。通过建立离在线人群服务为渠道提供精准流量筛选,再结合海量素材库与个性化推荐算法,能将广告曝光点击率从行业普遍的2%以下提升至10%以上。另一个重点策略“拉承一体”,则巧妙解决了用户引入后在登录环节大量流失的痛点。通过封装链接SDK统一入口,并借助“用户信息总线服务”跨域传递用户行为数据,让运营得以在用户激活的瞬间进行个性化承接,填补了引流与用户成长之间的空白。 整体而言,文章的价值不在于具体的技术实现,而在于其展现的系统化思考框架:如何用公式量化增长目标,如何构建体系化的流量引入路径,以及如何通过技术手段将运营抓手前置和深化。这对所有从事用户增长工作的人都有很强的借鉴意义。