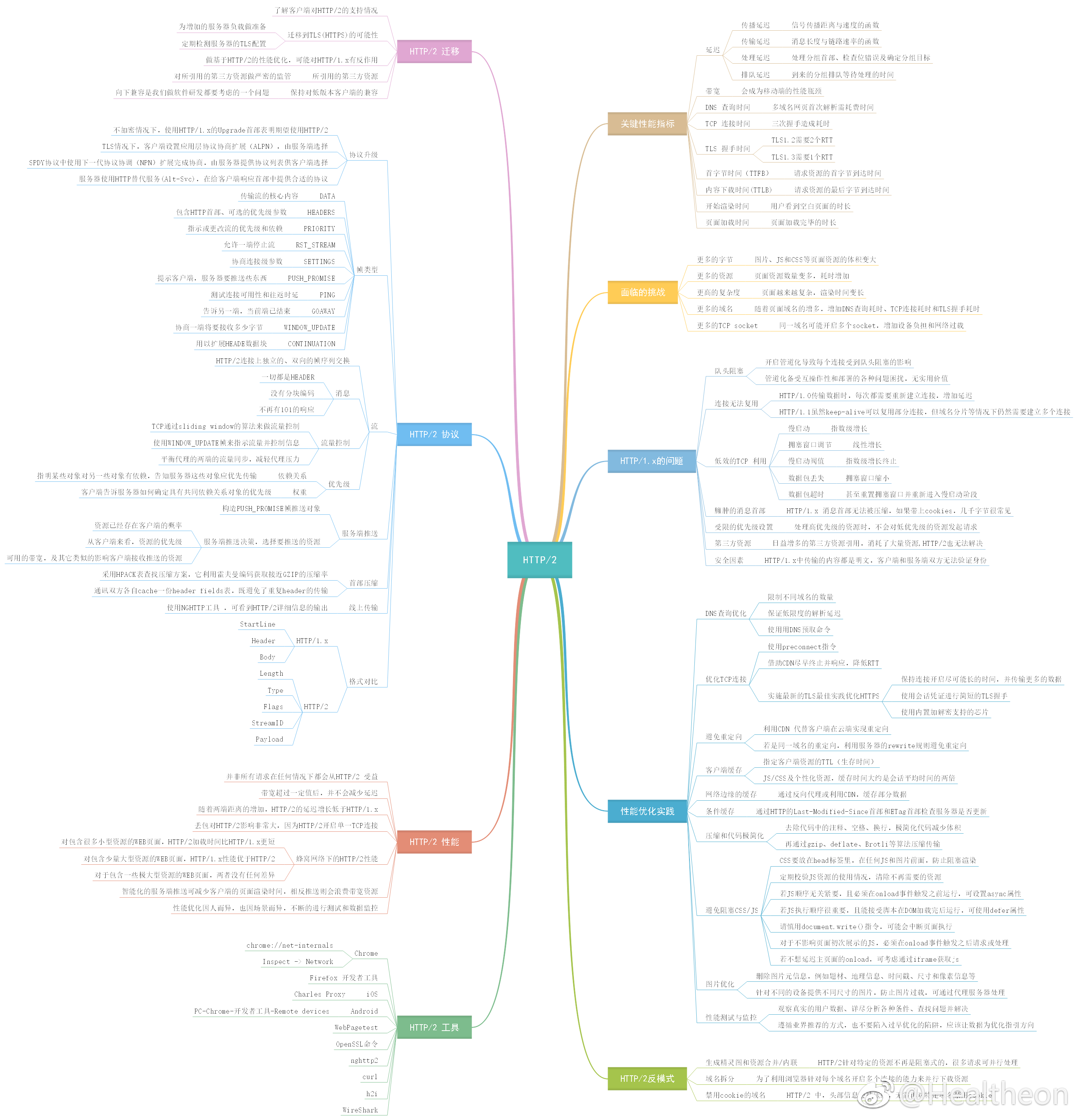
Http/2知识图谱
这篇讲的是HTTP/2环境下依然有效的十大通用性能优化规则。作者从HTTP/2与HTTP/1.x的显著差异出发,提炼出一系列核心实践。 文章具体列出了这些优化点:包括通过优化DNS查询来避免请求阻塞,充分利用HTTP/2的单TCP连接特性,以及谨慎处理跨域重定向。它强调了客户端与CDN边缘缓存的必要性,并提到了使用条件缓存、gzip压缩和针对性图片优化等具体手段。同时,文章也客观指出,像激进的预获取资源这类做法,在HTTP/2下可能收效甚微且开销大。 文章的一个关键亮点是,除了正面规则,还专门指出了HTTP/2下应避免的反模式,并配有一张清晰的知识图谱。这为开发者提供了直接的避坑指南。对于追求Web性能优化的工程师来说,这份结合了新旧协议考量的规则清单,具有很强的实操参考价值。