一、什么是防盗链
网站资源都有域的概念,浏览器加载一个站点时,首先加载这个站点的首页,一般是index.html或者index.php等。页面加载,如果仅仅是加载一个index.html页面,那么该页面里面只有文本,最终浏览器只能呈现一个文本页面。丰富的多媒体信息无法在站点上面展现。
那么我们看到的各类元素丰富的网页是如何在浏览器端生成并呈现的?其实,index.html在被解析时,浏览器会识别页面源码中的img,script等标签,标签内部一般会有src属性,src属性一般是一个绝对的URL地址或者相对本域的地址。浏览器会识别各种情况,并最终得到该资源的唯一地址,加载该资源。具体的加载过程就是对该资源的URL发起一个获取数据的请求,也就是GET请求。各种丰富的资源组成整个页面,浏览器按照html语法指定的格式排列获取到各类资源,最终呈现一个完整的页面。因此一个网页是由很多次请求,获取众多资源形成的,整个浏览器在一次网页呈现中会有很多次GET请求获取各个标签下的src资源。
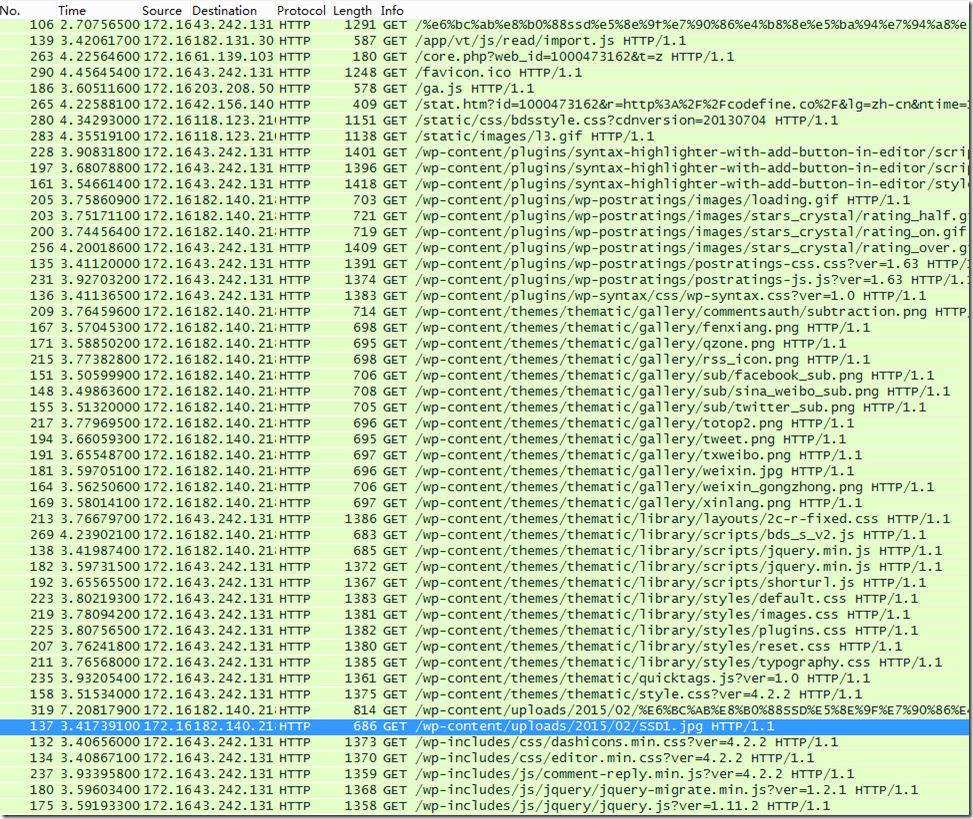
上图是一篇本站的博客网页呈现过程中的抓包截图。可以看到,大量的加载css、js和图片类资源的get请求。
观察其中的请求目的地址,可以发现有两类,一个是本站的43.242段的IP地址,这是本站的空间地址,即向本站自身请求资源,一般来说这个是必须的,访问资源由自身托管。另外一类是访问182的网段拉取数据。这类数据不是托管站内的,是在其他站点的。浏览器在页面呈现的过程,拉取非本站的资源,这就称“盗链”。
准确的说,只有某些时候,这种跨站访问资源,才被称为盗链。假设B站点作为一个商业网站,有很多自主版权的图片,自身展示用于商业目的。而A站点,希望在自己的网站上面也展示这些图片,直接使用:
<imgsrc="http://b.com/photo.jpg"/>这样,大量的客户端在访问A站点时,实际上消耗了B站点的流量,而A站点却从中达成商业目的。从而不劳而获。这样的A站点着实令B站点不快的。如何禁止此类问题呢?
HTTP协议和标准的浏览器对于解决这个问题提供便利,浏览器在加载非本站的资源时,会增加一个头域,头域名字固定为:
Referer: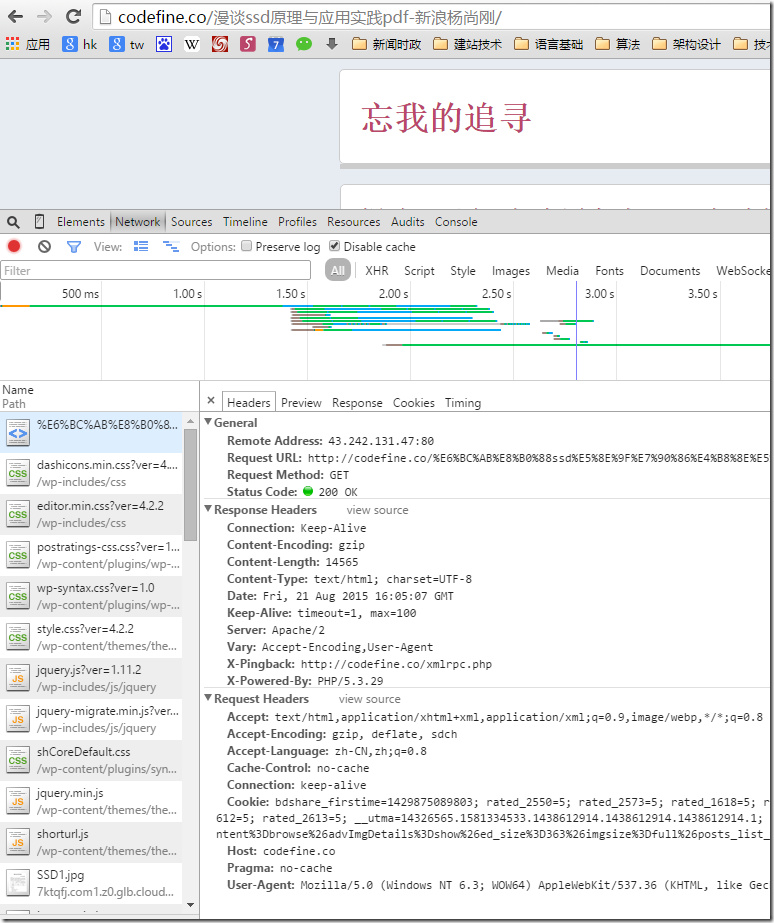
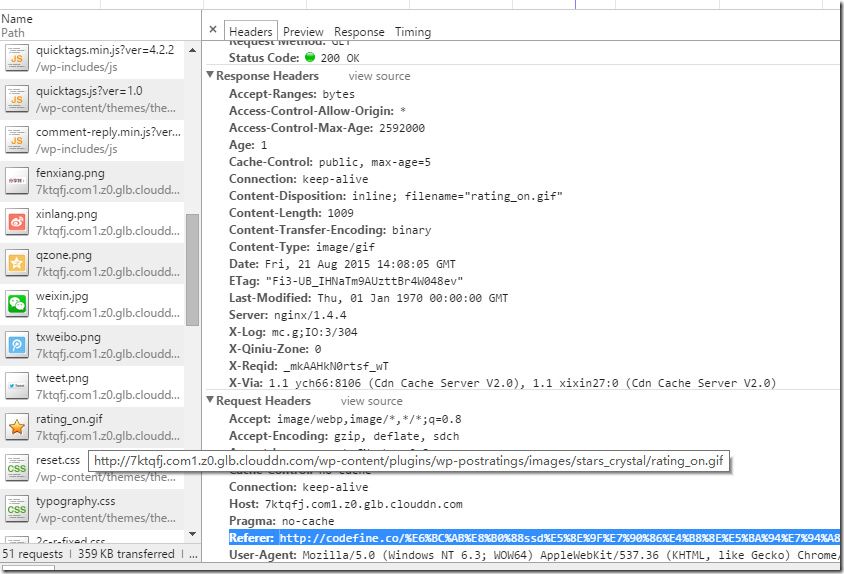
这个referer标签正是为了告诉请求响应者(被拉取资源的服务端),本次请求的引用页是谁,资源提供端可以分析这个引用者是否“友好”,是否允许其“引用”,对于不允许访问的引用者,可以不提供图片,这样访问者在页面上就只能看到一个图片无法加载的浏览器默认占位的警告图片,甚至服务端可以返回一个默认的提醒勿盗链的提示图片。
一般的站点或者静态资源托管站点都提供防盗链的设置,也就是让服务端识别指定的Referer,在服务端接收到请求时,通过匹配referer头域与配置,对于指定放行,对于其他referer视为盗链。
(未完待续,下一篇介绍跨域访问。)