人脸识别经过近 40 年的发展,取得了很大的发展,涌现出了大量的识别算法。这些算法的涉及面非常广泛,包括模式识别、图像处理、计算机视觉、人工智能、统计学习、神经网络、小波分析、子空间理论和流形学习等众多学科。所以很难用一个统一的标准对这些算法进行分类。根据输入数据形式的不同可分为基于静态图像的人脸识别和基于视频图像的人脸识别。因为基于静态图像的人脸识别算法同样适用于基于视频图像的人脸识别,所以只有那些使用了时间信息的识别算法才属于基于视频图像的人脸识别算法。接下来分别介绍两类人脸识别算法中的一些重要的算法。
特征脸
特征脸方法利用主分量分析进行降维和提取特征。主分量分析是一种应用十分广泛的数据降维技术,该方法选择与原数据协方差矩阵前几个最大特征值对应的特征向量构成一组基,以达到最佳表征原数据的目的。因为由主分量分析提取的特征向量返回成图像时,看上去仍像人脸,所以这些特征向量被称为“特征脸”。
在人脸识别中,由一组特征脸基图象张成一个特征脸子空间,任何一幅人脸图象(减去平均人脸后)都可投影到该子空间,得到一个权值向量。计算此向量和训练集中每个人的权值向量之间的欧式距离,取最小距离所对应的人脸图像的身份作为测试人脸图像的身份。
下图给出了主分量分析的应用例子。图中最左边的为平均脸,其他地为对应 7 个最大特征值的特征向量。


主分量分析是一种无监督学习方法,主分量是指向数据能量分布最大的轴线方向,因此可以从最小均方误差意义下对数据进行最优的表达。但是就分类任务而言,由主分量分析得到的特征却不能保证可以将各个类别最好地区分开来。
线性鉴别分析是一种著名的模式识别方法,通过将样本线性变换到一个新的空间,使样本的类内散布程度达到最小,同时类间散布程度达到最大,即著名的 Fisher 准则。
 |
标准特征脸 |
 |
同一个人不同图像之间的的特征脸 |
 |
不同人的图像之间的特征脸 |
弹性图匹配
Lades 等人针对畸变不变性的物体识别问题提出了一种基于动态连接结构的弹性图匹配方法,并将其应用于人脸识别。所有人脸图像都有相似的拓扑结构。人脸都可表示成图,图中的节点是一些基准点(如眼睛,鼻尖等),图中的边是这些基准点之间的连线。
每个节点包含 40 个 Gabor 小波(一种数字信号变换方法)系数,包括相位和幅度,这些系数合起来称为一个 Jet ,这些小波系数是原始图像和一组具有 5 个频率、 8 个方向的 Gabor 小波卷积(一种数字信号处理算子)得到的。这样每幅图就像被贴了标签一样,其中的点被 Jets 标定,边被点之间的距离标定。所以一张人脸的几何形状就被编码为图中的边,而灰度值的分布被编码为图中的节点。如下图所示:
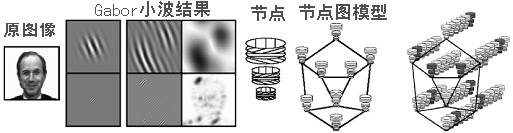
弹性图匹配方法中人脸的弹性束图表示
为了识别一张新的人脸,需要从该人脸中找到基准点,提取出一个人脸图,这可用弹性图匹配得到。弹性图匹配的目的是在新的人脸中找到基准点,并且提取出一幅图,这幅图和现有的人脸束图之间的相似度最大。经过弹性图匹配后,新的人脸的图就被提取出来了,此图就表征了新的人脸,用它作为特征进行识别。进行识别时,计算测试人脸和现有人脸束图中的所有人脸之间的相似度,相似度最大的人脸的身份即为测试人脸的身份。
由于该方法利用 Gabor 小波变换来描述面部特征点的局部信息,因此受光照影响较小。此外,在弹性匹配的过程中,网格的形状随着特征点的搜索而不断变化,因此对姿态的变化也具有一定的自适应性。该方法的主要缺点是搜索过程中代价函数优化的计算量巨大,因而造成识别速度较慢,导致该方法的实用性不强。
3D 形态模型
人脸本质上是 3D 空间中的一个表面,所以原则上用 3D 模型能更好地表征人脸,特别是处理人脸的各种变化,如姿势、光照等。 Blanz 等人提出了一种基于 3D 形态模型的方法,该方法将形状和纹理用模型参数编码,同时提出了一个能从单张人脸图像还原模型参数的算法。形状和纹理参数可用来进行人脸的识别。为了处理由于这些参数导致的图像之间差异的极端情形,通常是预先产生一个通用的模型。而进行图像分析时,给定一张新的图像,一般的做法是用通用模型去拟合新的图像,从而根据模型来参数化新的图像。
基于视频图像的识别算法
一个典型的基于视频图像的人脸识别系统一般都是自动检测人脸区域,从视频中提取特征,最后如果人脸存在则识别出人脸的身份。在视频监控、信息安全和出入控制等应用中,基于视频的人脸识别是一个非常重要的问题,也是目前人脸识别的一个热点和难点。基于视频比基于静态图像更具优越性,因为 Bruce 等人和 Knight 等人已证明,当人脸被求反或倒转时,运动信息有助于(熟悉的)人脸的识别。虽然视频人脸识别是基于静态图像的人脸识别的直接扩展,但一般认为视频人脸识别算法需要同时用到空间和时间信息,这类方法直到近几年才开始受到重视并需要进一步的研究和发展。目前视频人脸识别还有很多困难和挑战,具体来说有以下几种:
视频图像质量比较差:视频图像一般是在户外(或室内,但是采集条件比较差)获取的,通常没有用户的配合,所以视频人脸图像经常会有很大的光照和姿态变化。另外还可能会有遮挡和伪装。
人脸图像比较小:同样,由于采集条件比较差,视频人脸图像一般会比基于静态图像的人脸识别系统的预设尺寸小。小尺寸的图像不但会影响识别算法的性能,而且还会影响人脸检测,分割和关键点定位的精度,这必然会导致整个人脸识别系统性能的下降。
视频人脸识别起源于基于静态图像的人脸识别,即识别系统自动的检测和分割出人脸,然后用基于静态图像的识别方法进行识别。对这类方法的一个提高是加入了人脸跟踪。在这类系统中,通过利用姿态和从视频中估计到的深度信息合成一个虚拟的正面人脸。这个阶段的另外一个能提高识别率的方法是利用视频中充裕的帧图像,基于每帧图像的识别结果,使用 ” 投票 ” 机制。投票方法可以是确定的,但是概率投票方法一般来说更好。投票机制的一个缺点是计算结果的代价比较昂贵。
视频人脸识别的第二个发展阶段是利用多模态信息。因为人类一般会利用多种信息识别人的身份,所以一个多模态系统将比只利用人脸的识别系统性能更好。更重要的是利用多模态信息提供了一种方法,它能全面解决那些只靠人脸无法识别的任务。例如,在一个完全没有配合的环境(比如抢劫),歹徒的脸一般是蒙着的,这时唯一能进行无人脸识别的方法就是分析歹徒躯体的运动特性。除了指纹,人脸和声音是最常用于身份识别的信息。它们已经被用于很多多模态身份识别系统。 1997 年以来,每两年,就会召开一个专门关于基于视频和语音身份识别的国际会议。
最近几年,视频人脸识别进入第三个发展阶段,这个阶段方法的特点是同时采用空间信息(在每帧中)和时间信息(比如人脸特征的运动轨迹)。区别于概率投票方法的一个很大的不同之处在于,此类方法是在时间和空间的联合空间中描述人脸和识别人脸的。
视频图像的一个非常重要的特性是它的时间连续性,以及由此产生的人脸信息的不确定性。在人脸跟踪和识别中利用时间信息是视频人脸识别算法和基于静态图像的人脸识别算法的最大区别。目前这类算法大致可分为两类:
1、 跟踪 - 然后 - 识别,这类方法首先检测出人脸,然后跟踪人脸特征随时间的变化。当捕捉到一帧符合一定标准(大小,姿势)的图像时,用基于静态图像的人脸识别算法进行识别。这类方法中跟踪和识别是单独进行的,时间信息只在跟踪阶段用到。识别还是采用基于静态图像的方法,没用到时间信息。
2、 跟踪 - 且 - 识别,这类方法中,人脸跟踪和识别是同时进行的,时间信息在跟踪阶段和识别阶段都用到。