在上一篇文章 算法模式:前缀树 介绍一种关于特殊的树的算法模式。本篇文章,再介绍一种关于特殊的树的算法模式:并查集。
并查集
并查集算法,英文是 Union-Find,是解决动态连通性(Dynamic Conectivity)问题的一种算法。动态连通性是计算机图论中的一种数据结构,动态维护图结构中相连信息。简单的说就是,图中各个节点之间是否相连、如何将两个节点连接,连接后还剩多少个连通分量。
动态连通性其实可以抽象成给一幅图连线。假设用一个数组表示一堆节点,每个节点都是一个连通分量。初始化视图如下:
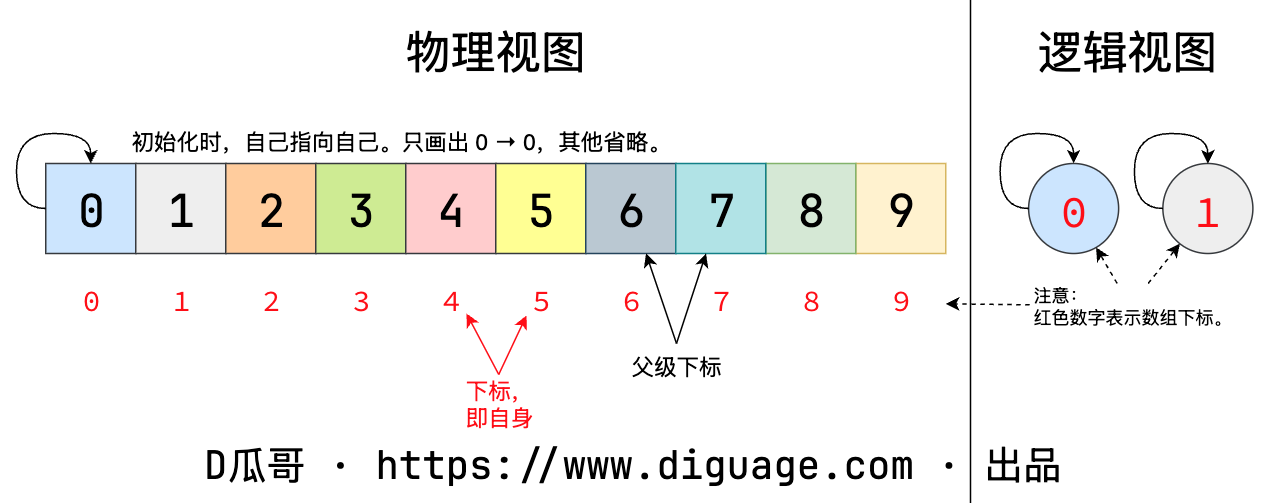
图 1. 并查集初始化
并查集的一个重要操作是 union(a, b),就是将节点 a 和节点 b 建立连接。如图所示:
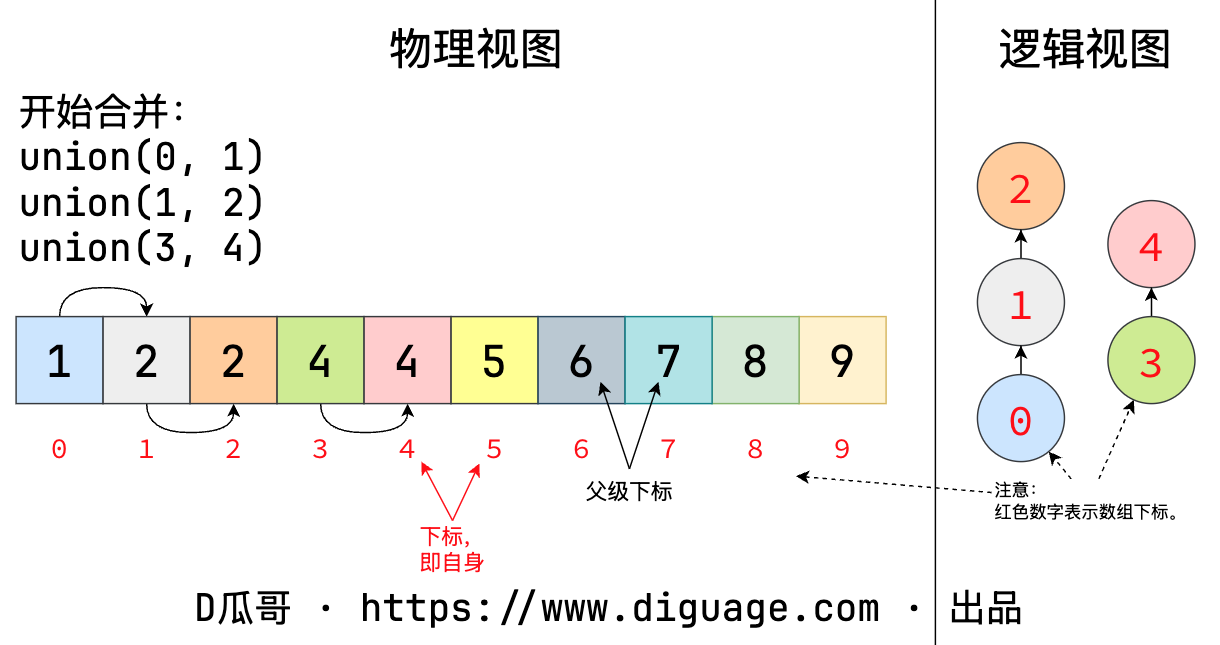
图 2. 并查集合并
union(a, b) 还可以将已经建立的两个“子网”进行连接:
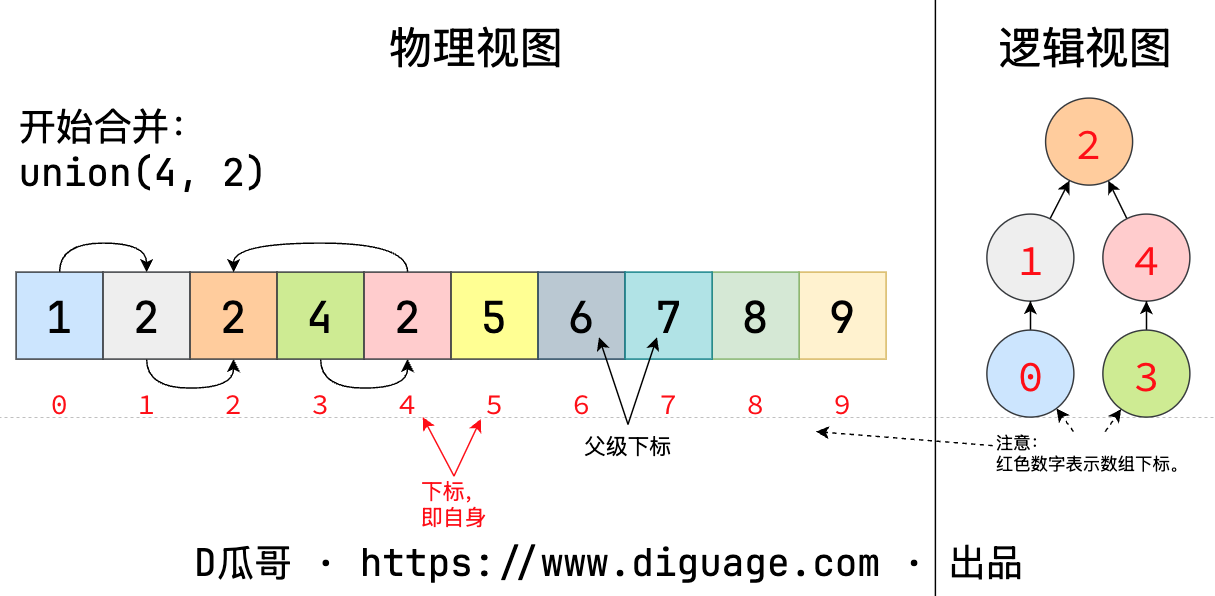
图 3. 并查集再合并
并查集除了 union,还有一个重要操作是 connnected(a, b)。判断方法也很简单,从节点 a 和 b 开始,向上查找,直到两个节点的根节点,判断两个根节点是否相等即可判断两个节点是否已经连接。为了加快这个判断速度,可以对其进行“路径压缩”,直白点说,就是将所有树的节点,都直接指向根节点,这样只需要一步即可到达根节点。路径压缩如图所示:
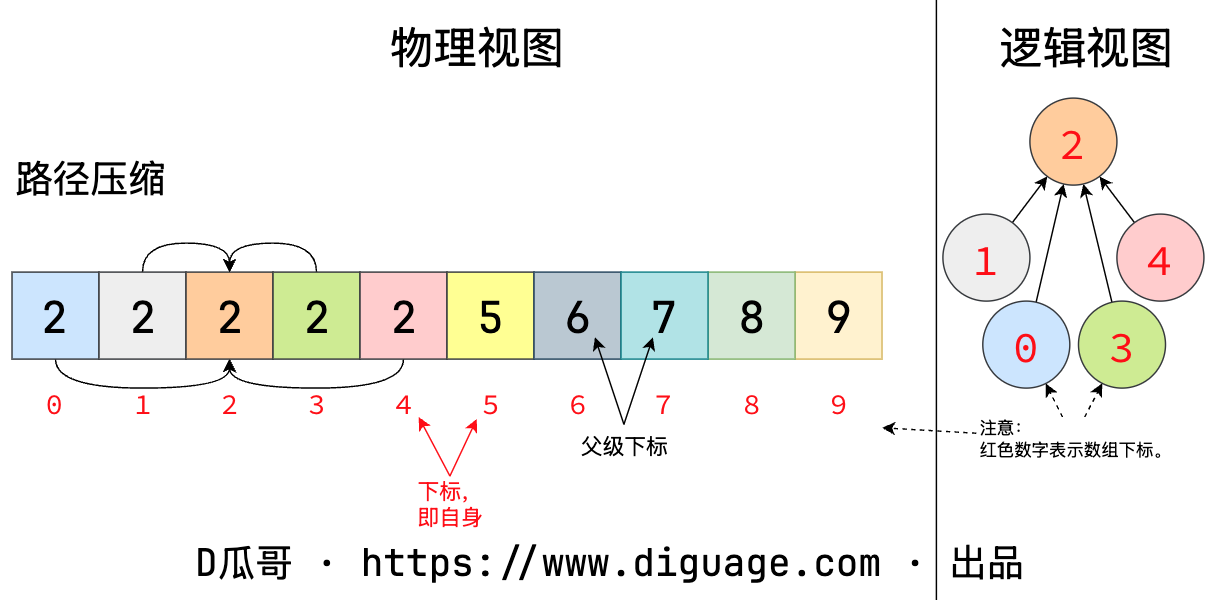
图 4. 并查集路径压缩
简单代码实现如下:
package com.diguage.labs;
import java.util.ArrayList;
import java.util.List;
/**
* 并查集
*
* PS:没想到代码竟然一次通过。
*
* @author D瓜哥 · https://www.diguage.com
* @since 2025-04-03 15:22:41
*/
public class UnionFind {
/**
* 连通分量
*/
private int size;
/**
* 每个节点及对应的父节点
*/
private int[] parent;
public UnionFind(int size) {
this.size = size;
parent = new int[size];
for (int i = 0; i < size; i++) {
parent[i] = i;
}
}
/**
* a 和 b 建立连接
*/
public void union(int a, int b) {
int ap = find(a);
int bp = find(b);
if (ap == bp) {
return;
}
parent[ap] = bp;
size--;
}
/**
* a 和 b 是否连通
*/
public boolean connected(int a, int b) {
int ap = find(a);
int bp = find(b);
return ap == bp;
}
/**
* 连通分量
*/
public int count() {
return size;
}
/**
* 查找节点 a 的根节点
*/
private int find(int a) {
int ap = parent[a];
if (a != ap) {
List<Integer> path = new ArrayList<>();
path.add(a);
// 向上查找根节点
while (parent[ap] != ap) {
path.add(ap);
ap = parent[ap];
}
// 路径压缩
// 只有一步,无需缩短路径
if (path.size() == 1) {
return ap;
}
for (Integer idx : path) {
parent[idx] = ap;
}
}
return ap;
}
public static void main(String[] args) {
UnionFind uf = new UnionFind(10);
uf.union(0, 1);
uf.union(1, 2);
uf.union(2, 3);
uf.union(3, 4);
uf.union(5, 6);
uf.union(6, 7);
uf.union(7, 8);
uf.union(8, 9);
uf.union(0, 5);
System.out.println(uf.count() + ", " + uf.connected(0, 9));
System.out.println(uf.count() + ", " + uf.connected(2, 9));
System.out.println(uf.count() + ", " + uf.connected(3, 9));
System.out.println(uf.count() + ", " + uf.connected(5, 9));
}
}